超干信息收集,让资产 say NO! 前言 俗话说,信息收集是渗透的过程中的重中之重!好的信息收集可以在渗透过程中让我们行云流水。而且信息收集对条理度和深浅都有严格把关,我们应该尽量地有条理性地进行深度信息收集!以下就是我信息收集思路,尽量做到深入和有条理性。
攻防企业、政府、edusrc、企业src、小程序、公众号、app、供应链、国外企业、cnvd信息收集,应有尽有
内容框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1、资产形势分析
分析当前形势 一来就扯信息搜集,就有点太公式化了。所以我想说的是,无论我们做什么事情,都必须先就目前的情况对事情的目标有清晰的了解和挖掘!
目前,国内的资产主要分为政府 和企业 ,也是我们渗透的主要目标。而无论是哪一个,他们的内部资产都是错综复杂的,我们要做好信息收集就必须摸清楚他们内部的资产关系。
其次我们一般都很少碰政府的资产,因为政府这个特殊机构内部包含很多敏感文件,我们的一旦在渗透过程中出现什么纰漏,就很容易威胁到自己的人身安全。并且国家也对这方面也把关得很严。所以我们除了在一些护网的时候,有了授权书,正大光明地渗透之外,其实还是少触碰政府相关的资产,但是也要学习,说不定哪天就用上了呢。
那就先捣鼓捣鼓企业的信息收集。
企业的信息收集 前置 对于企业而言,内部的资产都离不开”控股”二字。每个企业都由主公司和多个子公司组成,而在每个子公司也可能会有子公司的存在。
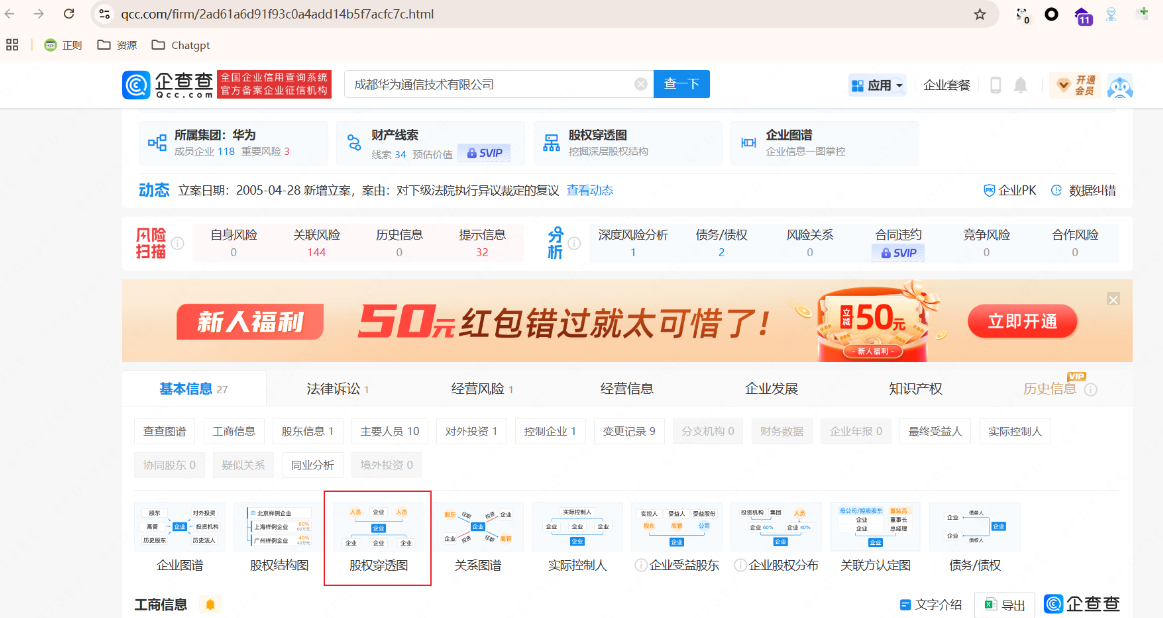
企业主域名收集 1、股权树: 作用:清晰地尽可能地通过公司名获取全部主域名 目标
在企查查中根据”股权穿透图”梳理股权树
采用”先上查后,向下查 “,确保上下查到底,资产大,小于50%股份子公司的直接舍弃 ,资产小就都收集 ,梳理成股权树,目的是为了得到大量的目标公司名。
当然这里只是让我们知道如何进行手工收集,为了图快捷,已经有相关的程序来查询公司股权树
ENscan_go
这个工具的具体使用就不用说了,作者的readme文件都写得很清楚了
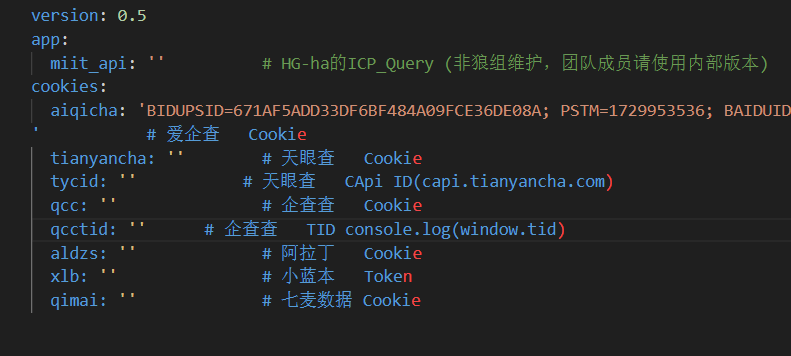
主要是要配置好以下文件
追求严谨的话,可以cookie都配置了,不过麻烦的就是,每次使用都要重新配置,不过也比手工便捷不少了,多谢师傅大大工具。
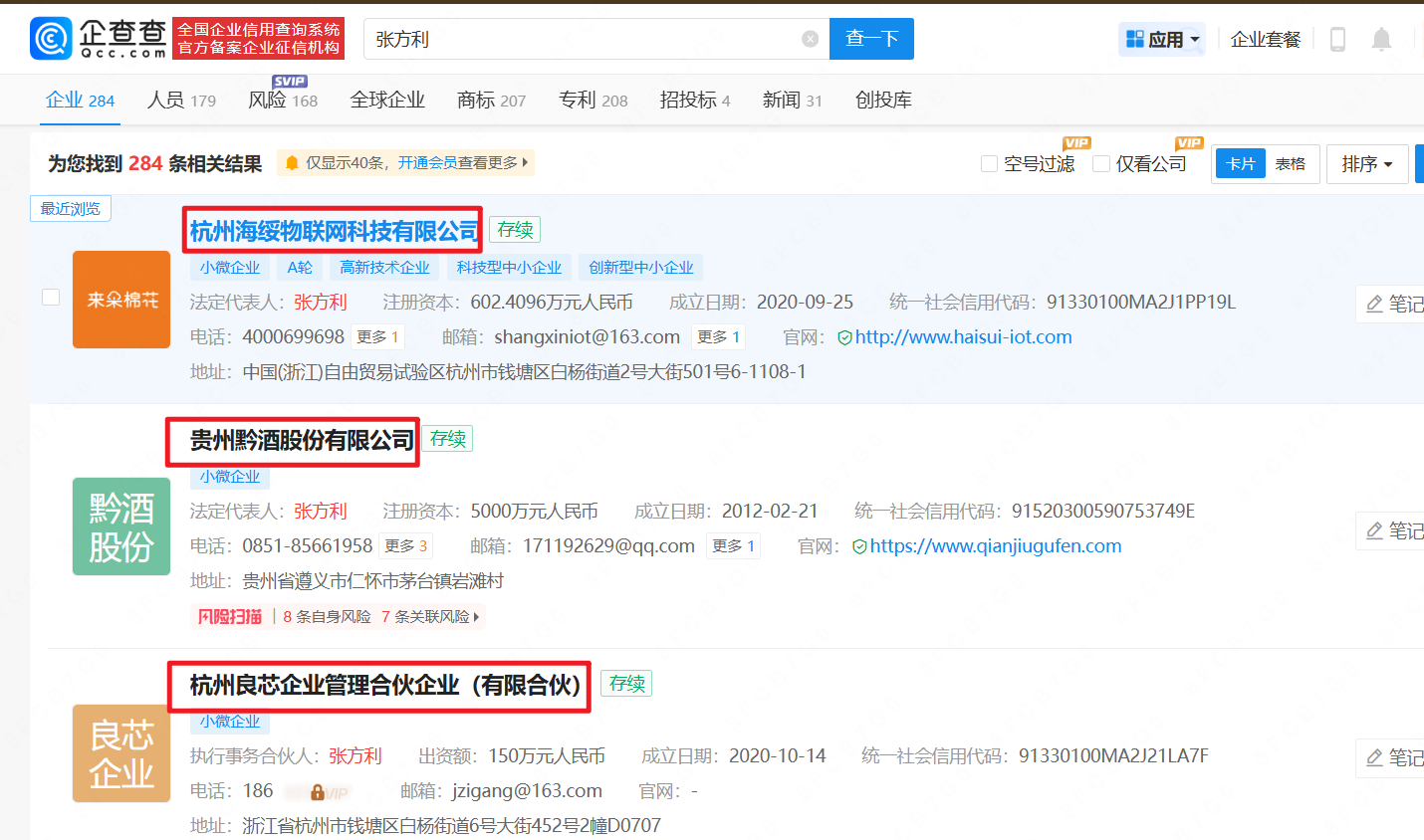
2、法人、企业高管 适用于中小型,大厂的法定人、高管大部分与其他公司有关联,容易有很多无关目标。然后一定要对上述的股权树重新梳理,得到最为完整的股权树。
通过在企查查中再次搜索法定人来获取公司名。
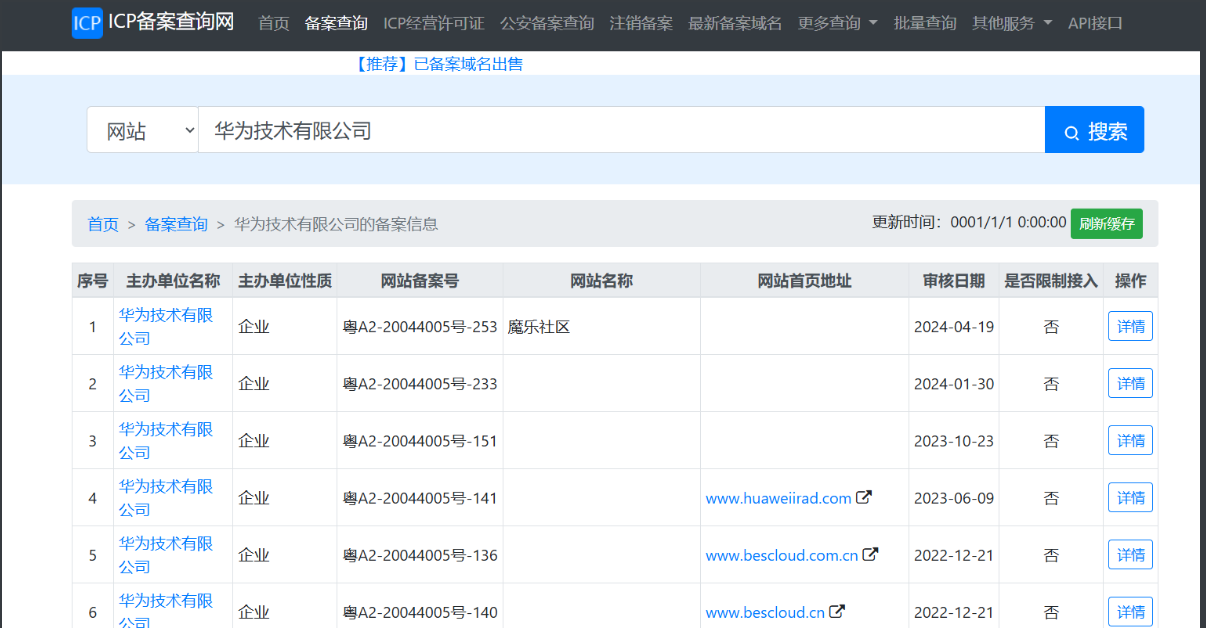
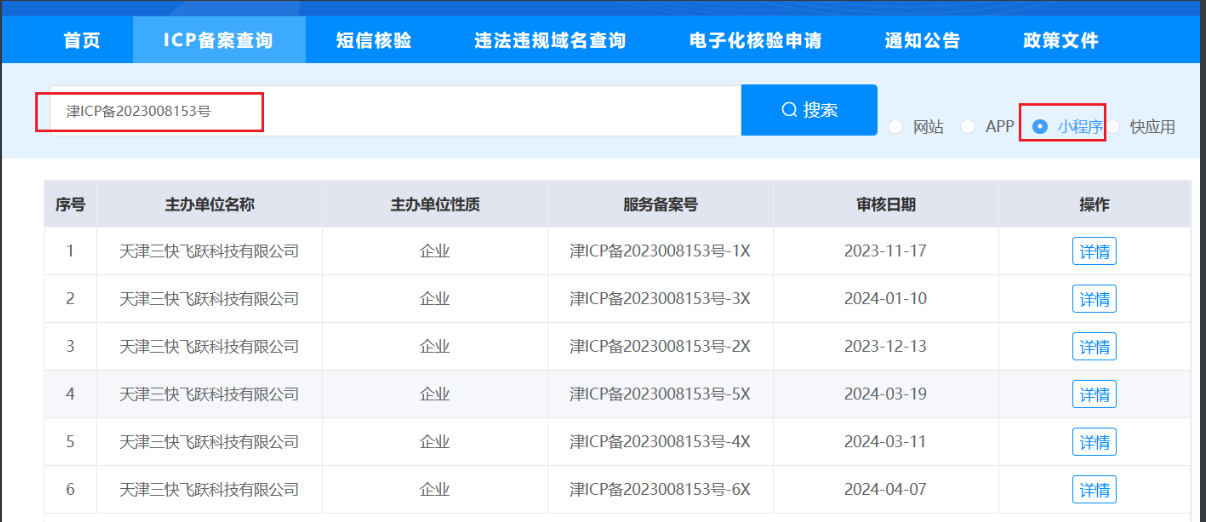
3、ICP备案 在国内,只要想合法搭建网站,就需要ICP备案。所以我们从icp备案查询来打开突破口。
ICP三大因素:企业名、备案号、域名。可以通过其中之一查找到另外两个,查询方式如下:
3.1官网 查询
使用之前收集的公司名,直接查询
再次利用得到的备案号再次查询
3.2批量查询
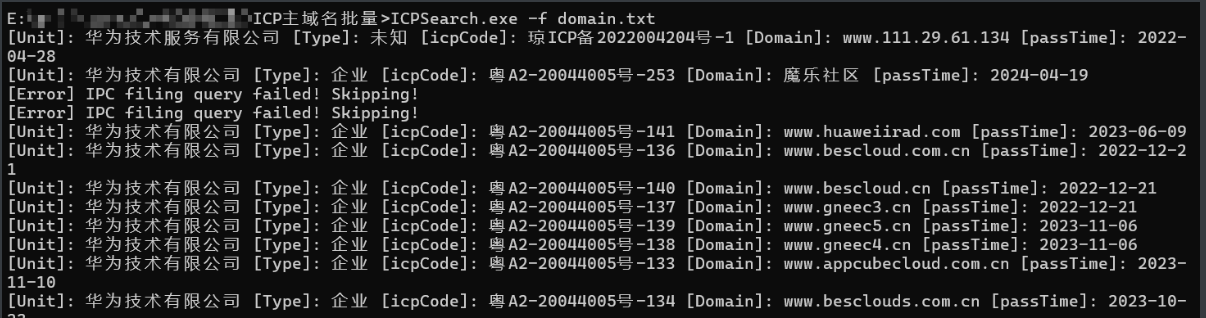
一个一个去查确实太慢了,所以我们利用icpsearch来直接批量查询
ICPsearch
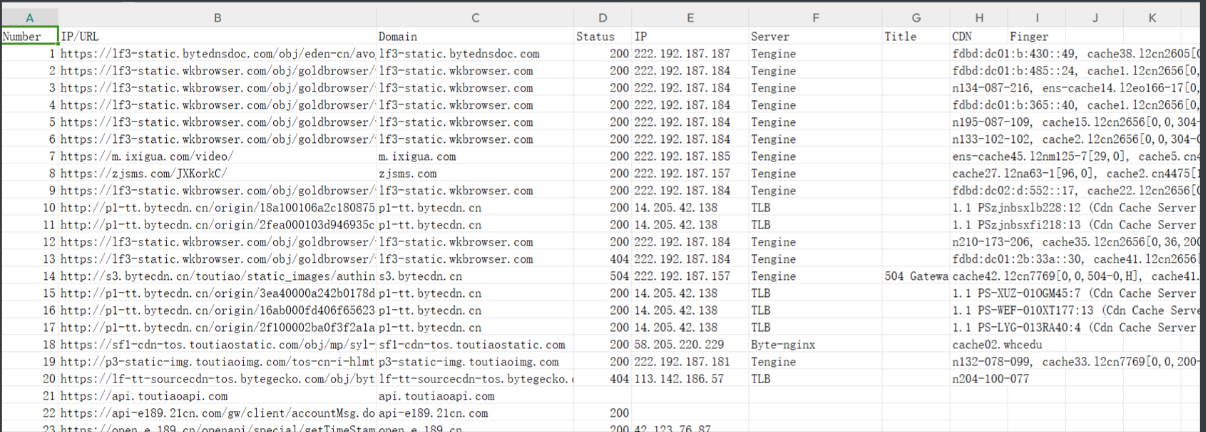
但是输出格式还是不好直接利用的,我们就写个小脚本(下面自写的所有小脚本先别急用,我为了可视化用python自动写了一个UI(在全端口扫描之前附得有github地址)来使用,希望有用),单独提取其中的备案号、域名、公司。
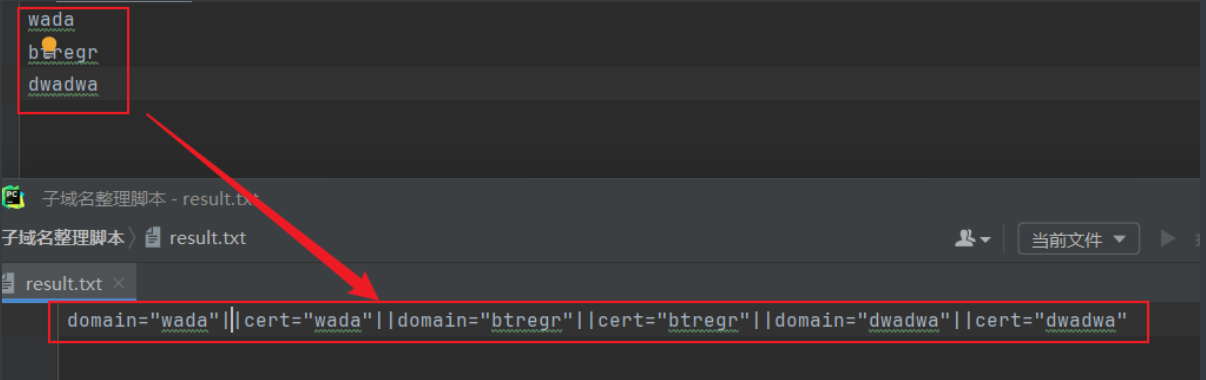
脚本:可把官网查询结果ctrl+c直接复制下来,保存在result.txt或者直接把工具得到的result.txt,然后使用该脚本来提取三大因素保存到result.xlsx
不过第一用公司名查询后,后面一定要通过备案号再查一次,一定一定!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import refrom openpyxl import Workbookr'\[Unit\]: ([\u4e00-\u9fff]+) \[Type\]' r'\[icpCode\]: ([京津沪渝黑吉辽蒙冀晋陕宁甘青新藏川贵云粤桂琼苏浙皖鲁闽赣湘鄂豫][A-Z]?\d?-?[ICP备]*\d{4,10}号)-' r'www\.((?:\d{1,3}\.){3}\d{1,3}|[a-zA-Z0-9-]+\.[a-zA-Z]{2,})' with open ('result.txt' , 'r' , encoding='utf-8' ) as file:max (len (companies), len (records), len (urls))'' ] * (max_len - len (companies)))'' ] * (max_len - len (records)))'' ] * (max_len - len (urls)))"Result Data" '公司名' , '备案号' , '网站地址' ])for company, record, url in zip (companies, records, urls):'result.xlsx' )print ("数据已提取并保存到 result.xlsx 文件中。" )
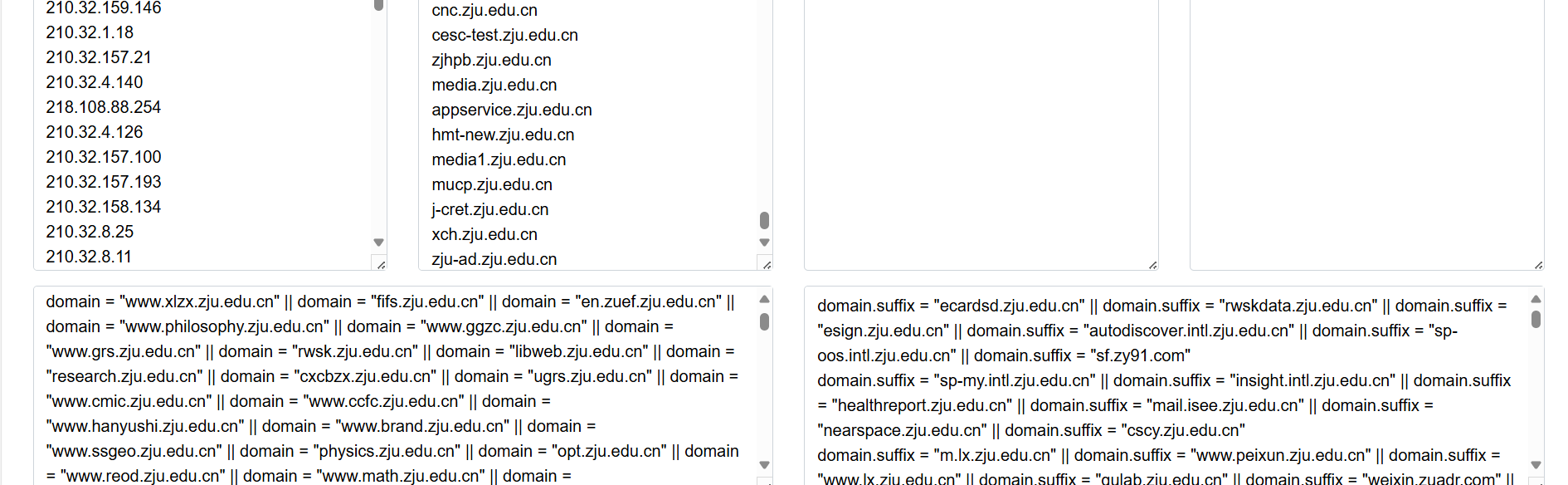
子域名 获取方法:1、fofa、hunter上直接导出、2、子域名挖掘工具
1、暗黑搜索引擎 主要围绕主域名、公用名、组织,进行手工查询,由于各大引擎的搜索语法大同小异,就以fofa为例:
使用搜索引擎时很重要的一点,都使用all模式 ,因为fofa默认展示1年内的资产、hunter则是一个月,使用all模式则可以获取更多边缘资产。
fofa语句1:domain=”“||cert=”“
由于一般主域名都很多,我们可以写一个搜索语法小脚本(针对domain、cert):
1 2 3 4 5 6 7 8 9 10 11 12 with open ('zhu.txt' , 'r' , encoding='utf-8' ) as file :lines = file .readlines()for line in lines :line = line .strip()'domain="{line}"||cert="{line}"' )with open ('result.txt' , 'w' , encoding='utf-8' ) as result_file:write ("||" .join(output))"数据已成功写入到 result.txt 文件中。" )
转化为:
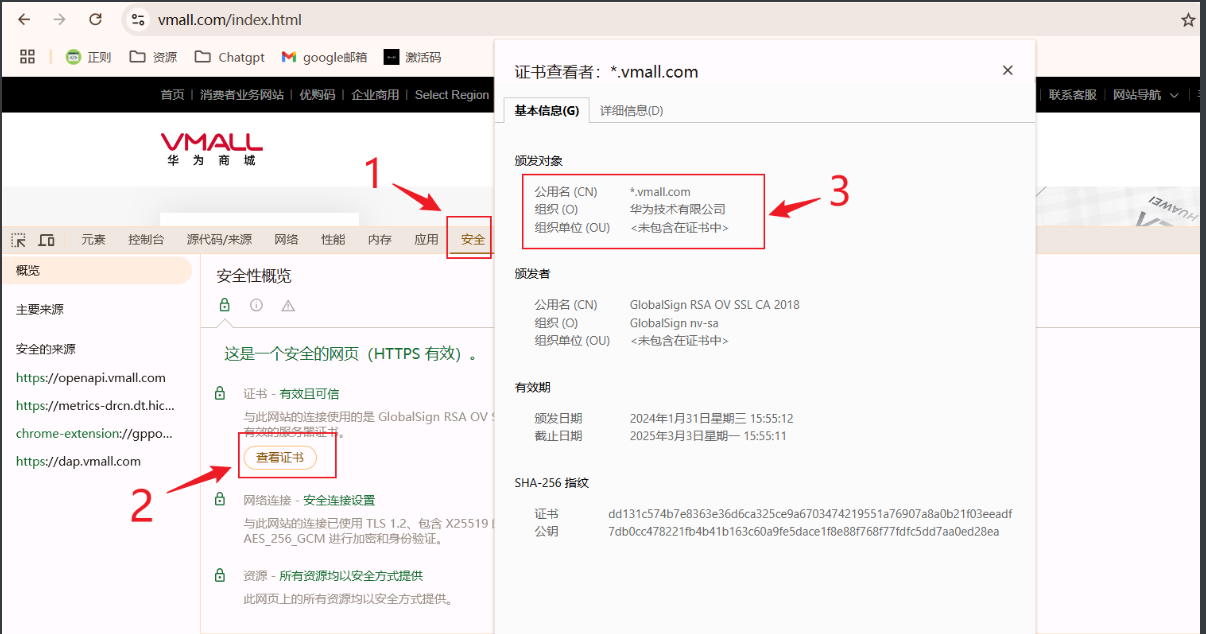
再从中去提取网站的证书中的 公用名 和 组织名,然后进一步搜索。
主要语法:fofa:**domain=”“||cert=”<公用名>”||cert=”<组织>”**,平常除了主域名、公用名之外,主要就关注https网站证书中的”组织”,因为有时候组织名可以让我们收集更多子域名。我们查看证书时,也要多综合收集组织名,一定要多搜集几个。
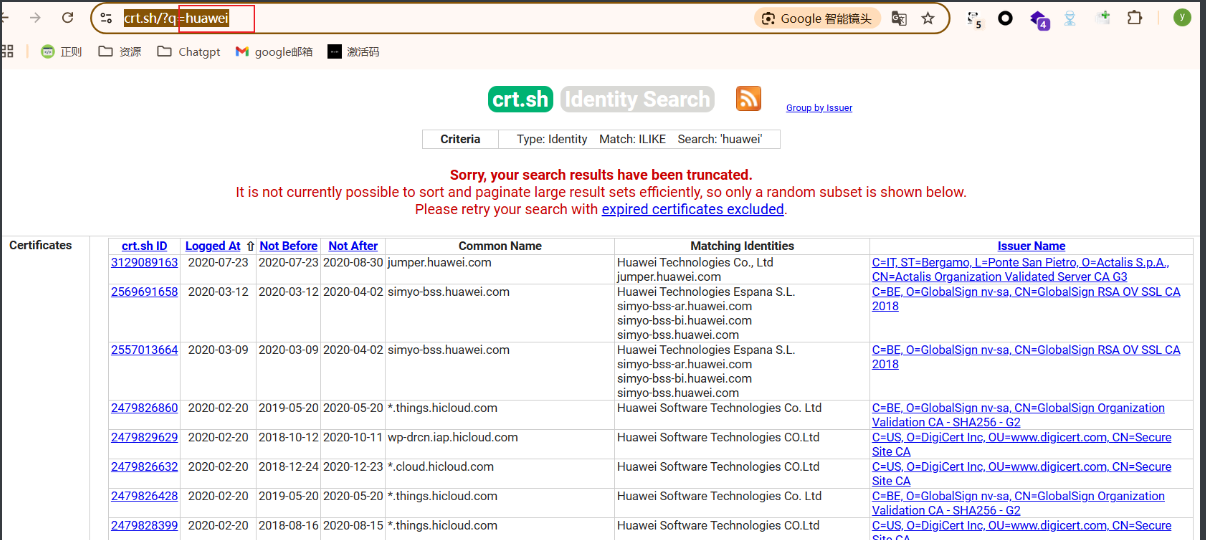
除了在看证书时候收集”组织名”,我们还可以通过官方的证书站(crt.sh)搜搜企业的拼音,查找一些组织名(特别是英文组织名)
再从中提取部分英文组织名搜集好然后拼接到脚本得到的语法中,集合就可以获取很全的子域名列表的了。
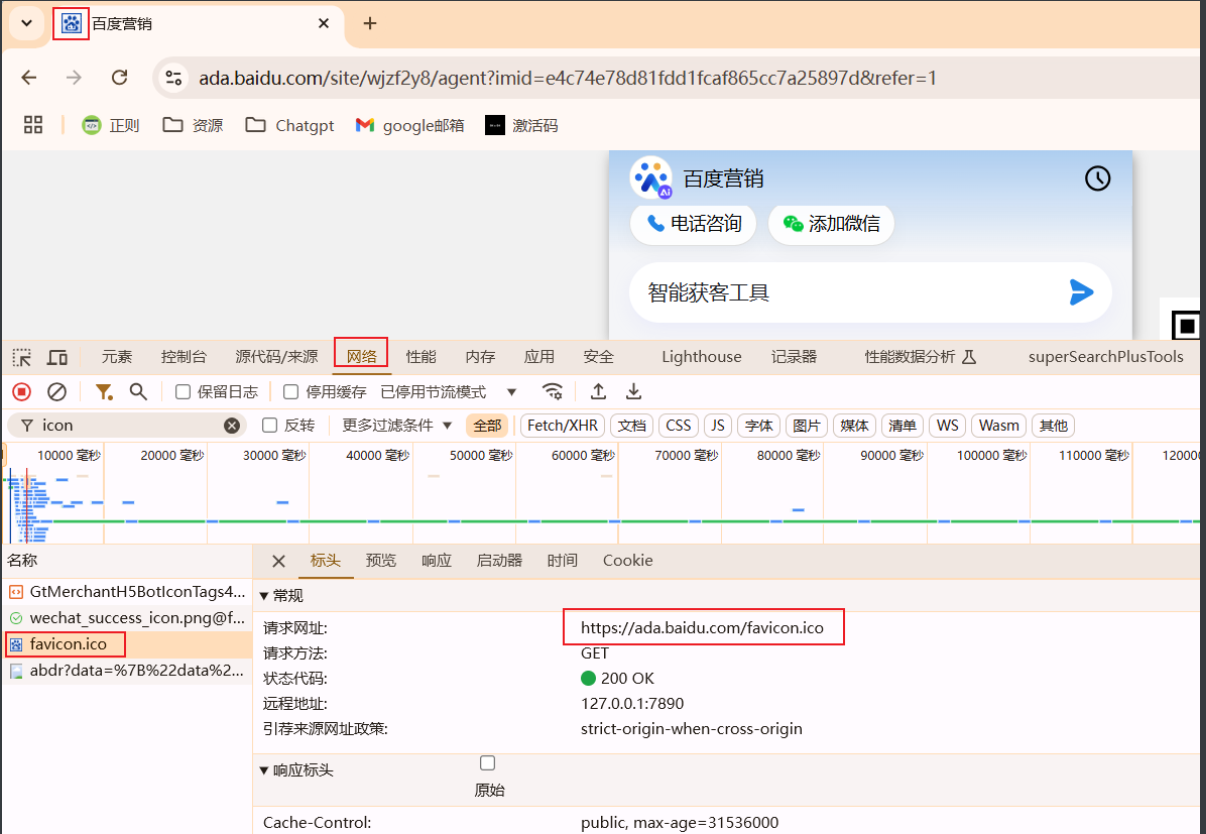
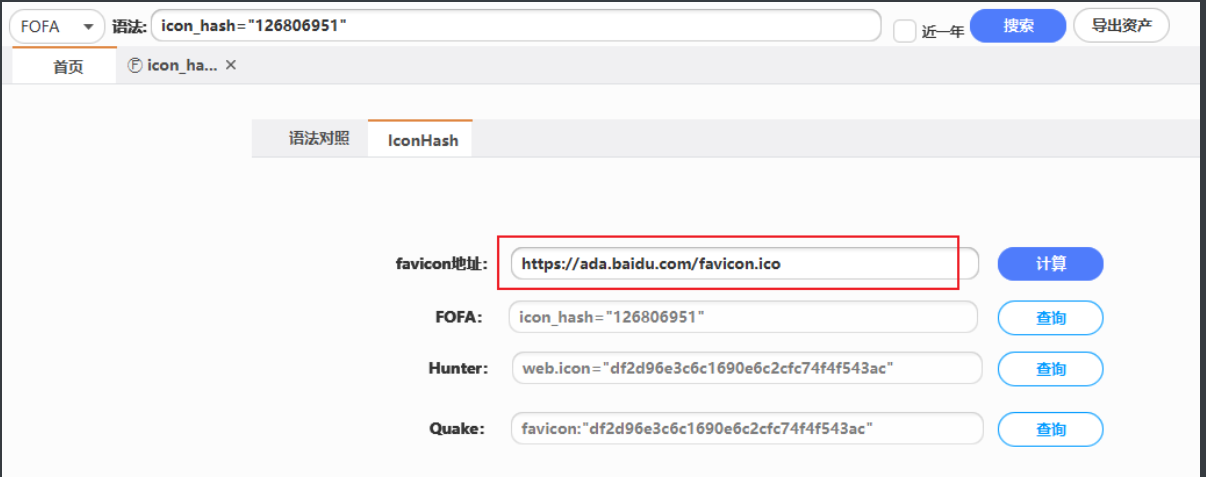
当然有条件可以加入图标icon 的搜索,只需要把下图的网站图片的地址的hash计算出来,添加到搜索中就行了:
fofa:domain=”“||cert=”<公用名>”||cert=”<组织>”||icon_hash=”<hash值>”
计算的脚本有很多,单个的话,可以使用密探足以
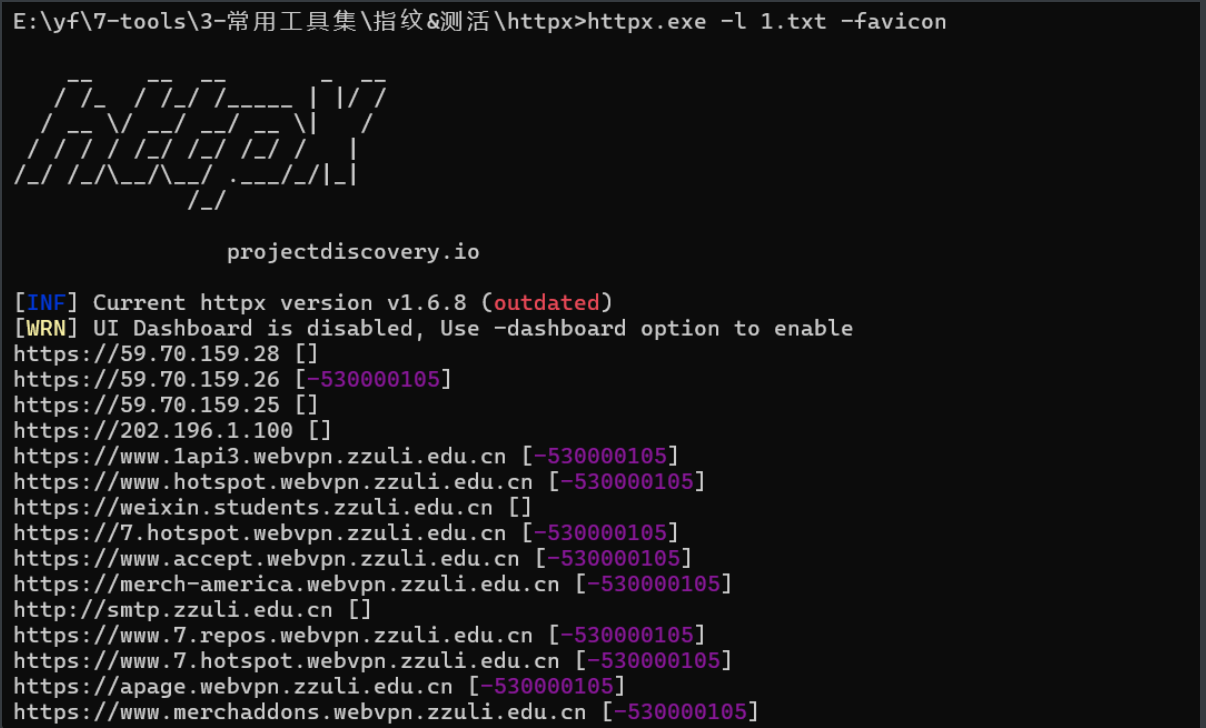
对于批量的ICON收集,则可以使用httpx,然后可以像之前c段统计一样,提取几个重复率高的值进行查询
最终的子域名收集:
简化的fofa语法:还有很多主域名和组织名没有加上去,只以一个站点为例,可见量之大
icon_hash=”126806951”||domain=”baidu.com”||cert=”baidu.com”||cert=”Beijing Baidu Netcom Science Technology Co., Ltd”
2、工具 2.1 Oneforall
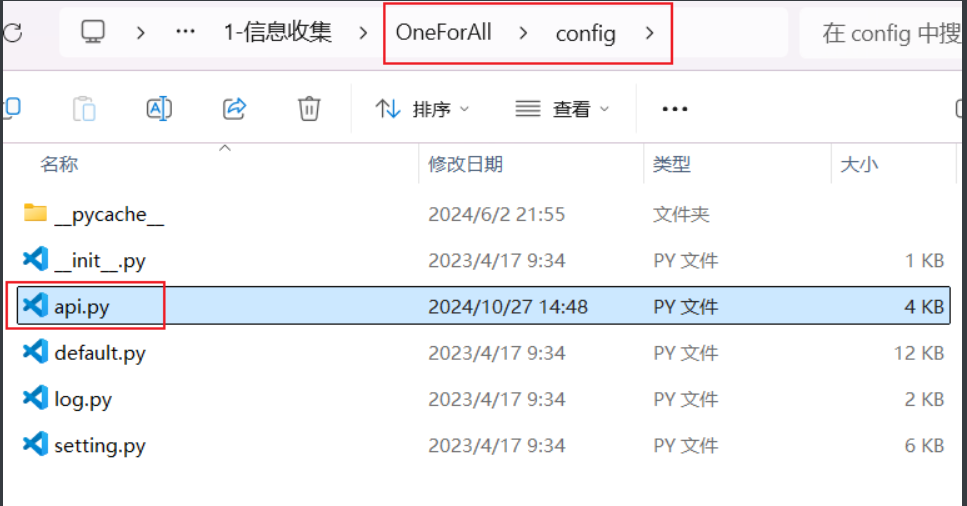
在配置好下图中的api,妥妥的子域名收集神器!!!其收集子域名的方式包含了:证书透明度、常规检查收集子域(域传送漏洞利用、检查跨域策略文件、检查HTTPS证书、检查内容安全策略、检查robots文件、检查sitemap文件、利用NSEC记录遍历DNS域)、网络爬虫收集子域名、利用DNS数据集收集子域、DNS查询、威胁情报平台、搜索引擎、子域名爆破、子域置换等等几乎全面的方法。
然后把搜集到的所有主域名仍targets.txt中,直接梭哈!
命令:python oneforall.py --targets targets.txt --brute True run
即可,不过谨记,一定不能完全依靠工具,必须要依靠手动的收集或者自写脚本处理!
2.2 Onelong
这也是一个综合性不错的信息工具,不过也要配置不少api。主要可以直接根据单个组织(结合了ENScan_GO 收集企业的一些方法,但是还是比不上原工具)来进行主子域名收集、指纹识别(一般)、app、小程序搜集,效果还不错!同时还集成了一些邮箱的收集、轻微漏洞扫描的功能。正对一些大型资产可用,中小型资产的话除了子域名收集还行以外,其他模块还是不如手动。
3、偏僻子域名寻找的方法
https://otx.alienvault.com/api/v1/indicators/domain/baidu.com/url_list?limit=100&page=1
替换上述的baidu.com,然后从burp的响应包中提取hostname即可,也可以直接把limit调大一下,一次性提取
总结: 用手动法,通过主域名的初步查询,从https子域名筛选出公用名和几个关键的中文组织名。再用crt.sh,通过指定主域名,获得几乎全部的英文组织名。这样再把他们全部串在一起用cert语法、icon语法查询得到搜索引擎的结果,其次就是使用oneforall,最后综合并去重上述的两个结果,即可得到最全的结果!!!!
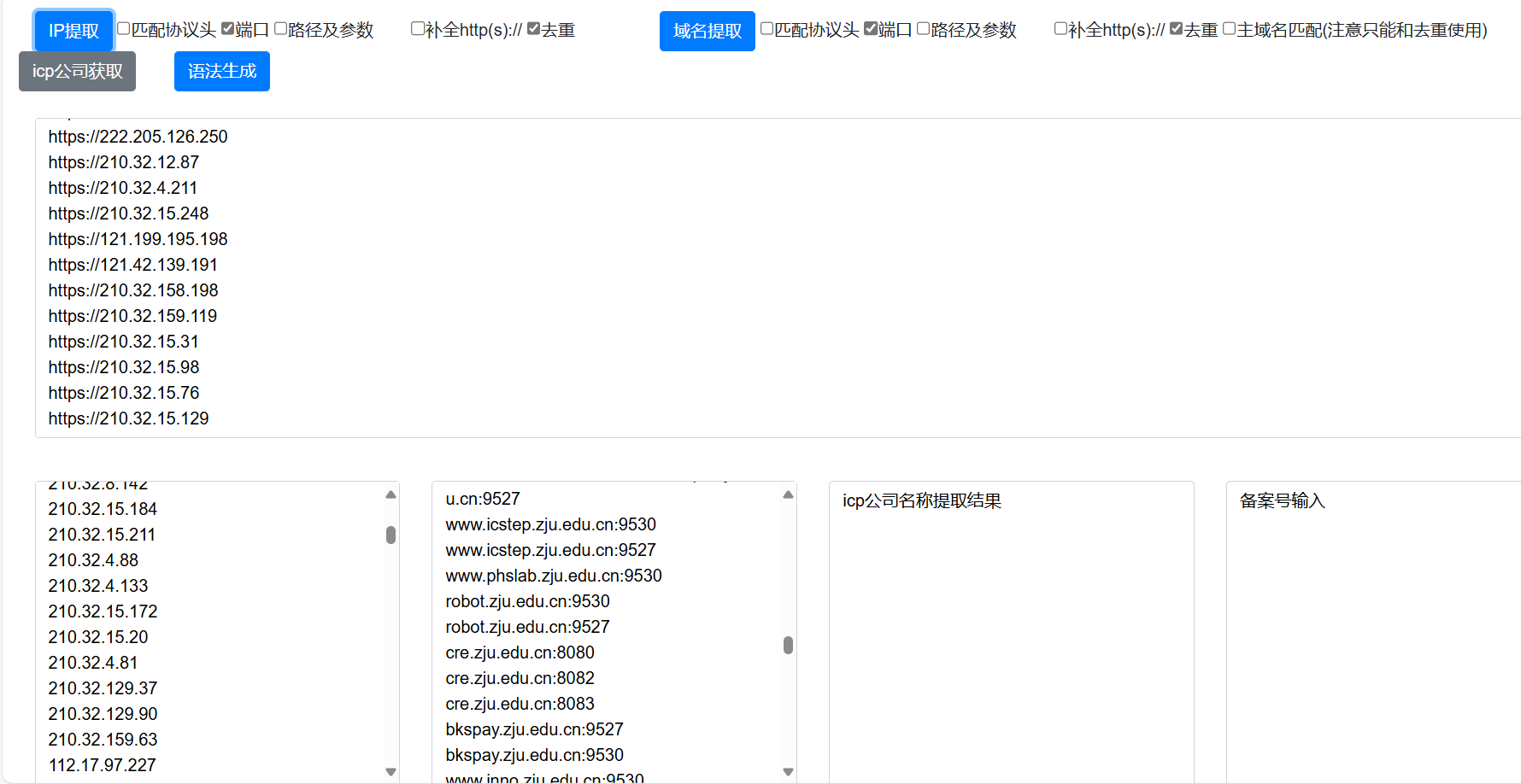
整理全部的url和IP(oneforall、搜索引擎导出),一定要把url和ip各自整理一个文本(因为oneforall和搜索引擎得到的ip不一定对,很大可能是cdn)。
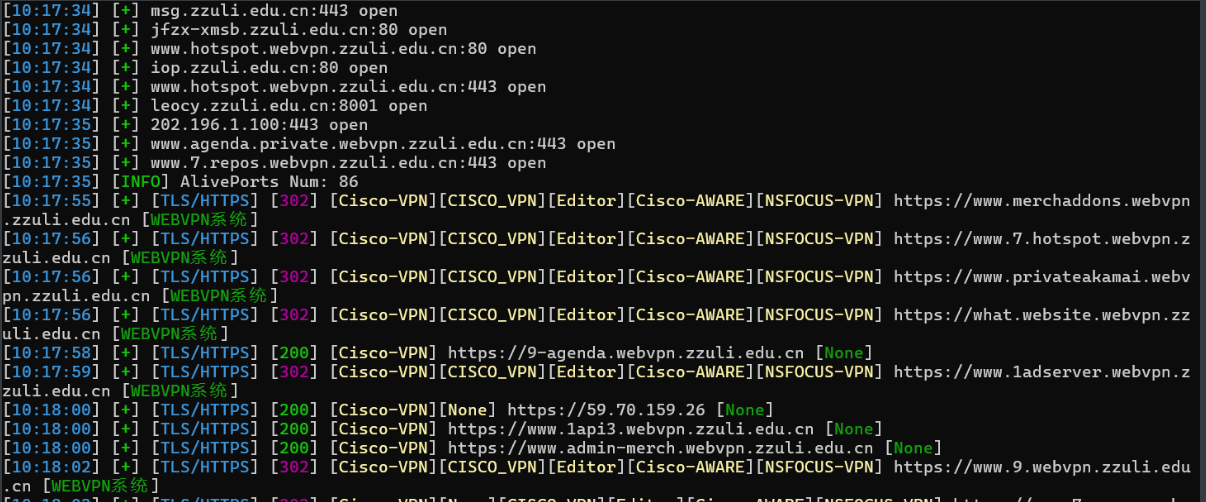
针对每一个ip分别生成http协议和https协议的列表,对url差哪个协议及添加协议(小脚本实现),整合一下得到目标(如果资产比较多,可以测活一下)——url.txt——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 with open ('web.txt' , 'r' ) as file :lines = file .readlines()for line in lines :line = line .strip() if line .startswith('http://' ):line ) 'https://' + line [7 :]) line .startswith('https://' ):line ) 'http://' + line [8 :]) else :'http://' + line ) 'https://' + line ) with open ('url.txt' , 'w' ) as file :for line in processed_lines:file .write (line + '\n' )
ip全端口+c段 流程 :得到url,单独提取其中的域名和IP,然后针对域名使用——Eeyes ——进行解析和cdn基础识别,去重整合得到部分完整的IP,提取占比大的c段,整合到ip中——ip.txt——,整体使用fscan全端口扫描,得到——port.txt——
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import rer"\b\d{1,3}(?:\.\d{1,3}){3}\b" r"(?:https?://)?([a-zA-Z0-9-]+\.[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})" with open ("url.txt" , "r" ) as infile:with open ("ip.txt" , "w" ) as ipfile:for ip in sorted (set (ip_matches)):"\n" )with open ("ym.txt" , "w" ) as domainfile:for domain in sorted (set (domain_matches)):"\n" )print ("IP 地址提取完成,结果已保存到 ip.txt" )print ("子域名提取完成,结果已保存到 ym.txt" )
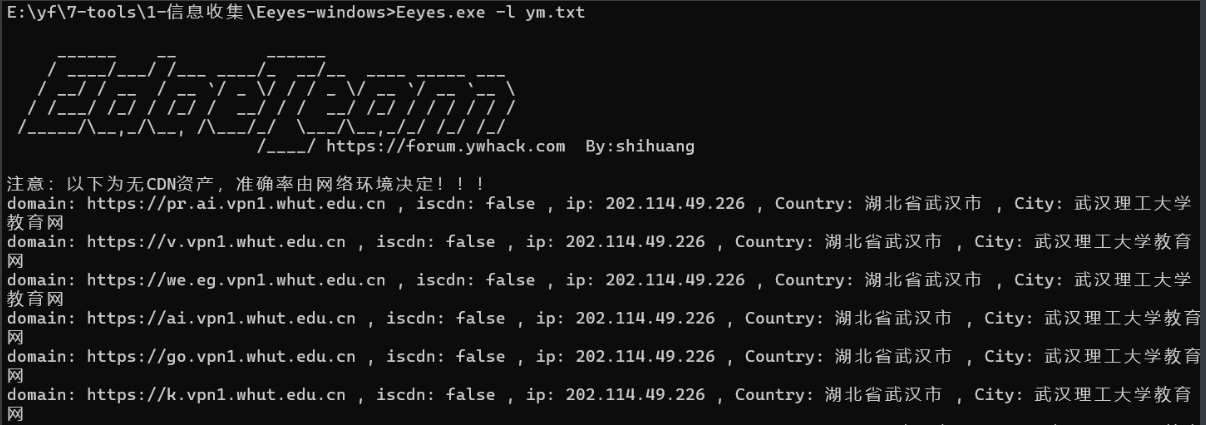
Eeyes,单独把上述的ym.txt扔入Eeyes中,提取ip
提取其中的ip脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import rer"\d+\.\d+\.\d+\.\d+" with open ("Eeyes.txt" , "r" ) as infile, open ("ip2.txt" , "w" ) as outfile:for match in sorted (set (matches)):match + "\n" )print ("提取完成,结果已保存到 ip2.txt" )
然后整合到ip.txt中就可
因为一些比较大的产业,很大可能会在卖服务器IP时是按c段买的,我们就可以利用这一点,说不定还可以获取不少隐蔽的站点等等。
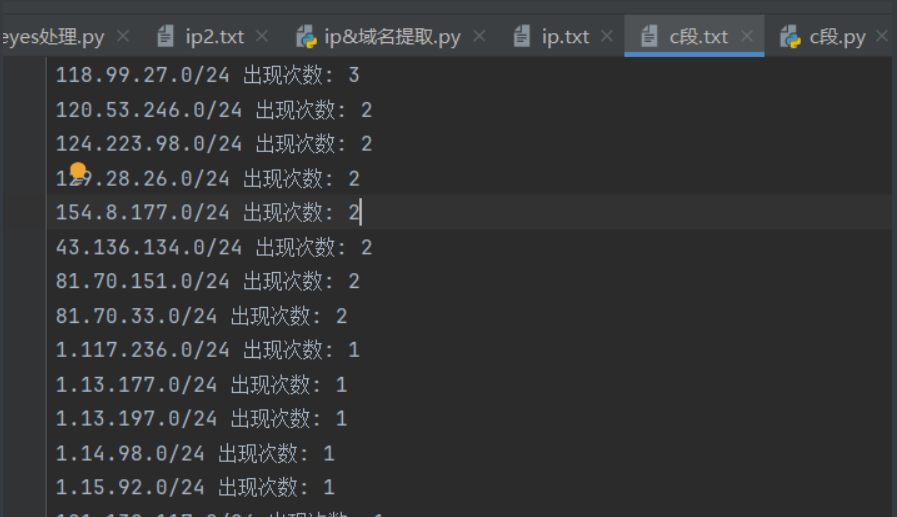
根据ip.txt中的数据,提取c段的重复率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 '''with open('ip.txt', 'r') as file :file .readlines()set ()for line in lines:1 )[0 ] "{base_ip}.0/24" with open('c段.txt', 'w') as file :for ip in c_segment_ips_set:file .write (ip + '\n')"完成 IP 转换和去重,结果已保存到 'Modified_IP.txt'" )from collections import Counterwith open('ip.txt', 'r') as file :file .readlines()for line in lines:1 )[0 ] "{base_ip}.0/24" item : item [1 ], reverse =True)with open('c段.txt', 'w') as file :for c_segment, count in sorted_c_segments:file .write (f"{c_segment} 出现次数: {count}\n" )"完成 C 段 IP 的统计、排序和保存,结果已保存到 'c段.txt'" )
挑选出现次数多得比较突出的c段,放于ip.txt中
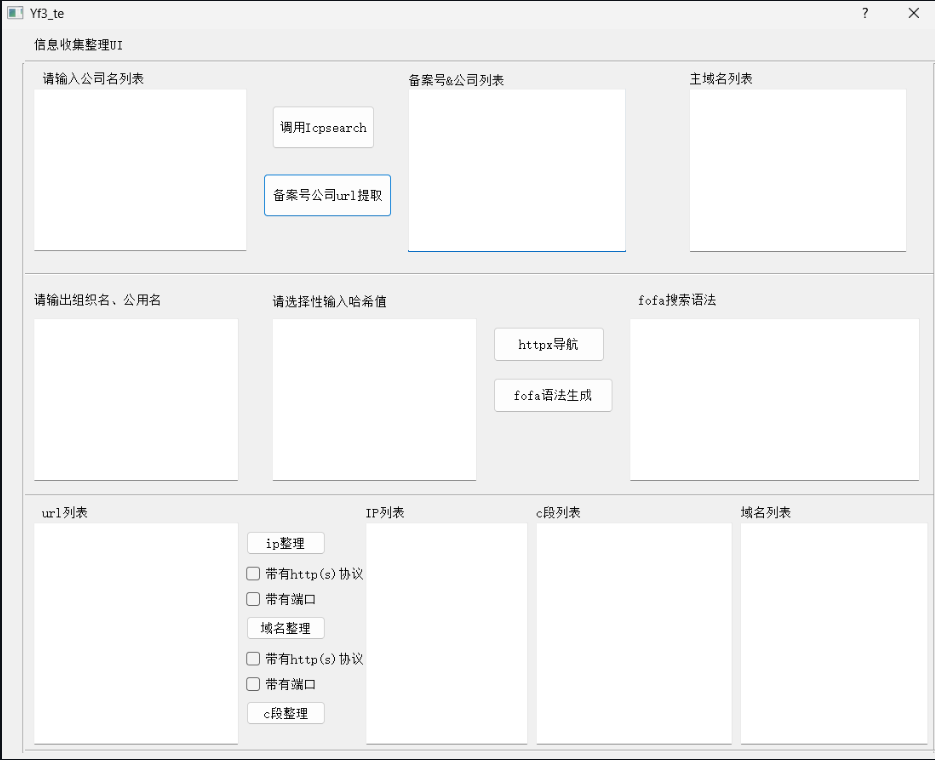
这里推荐一个我自写的python项目,用来实现可视化
项目地址:https://github.com/Yf3te/Yf_UI/
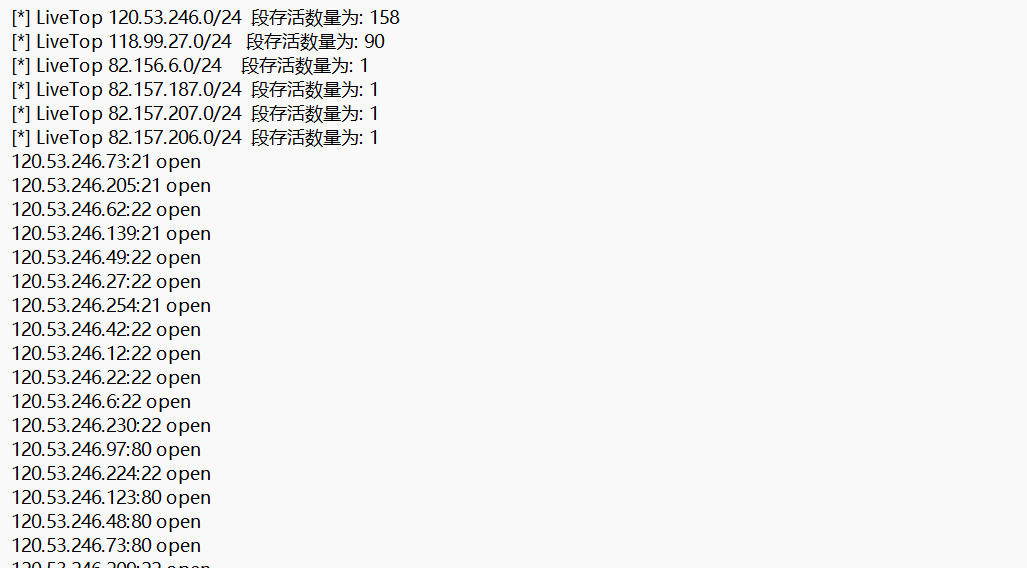
1 fscan .exe -hf ip.txt -t 3000 -p 1 -65535 -num 100 -np -o port.txt
扫描结果:
得到port.txt
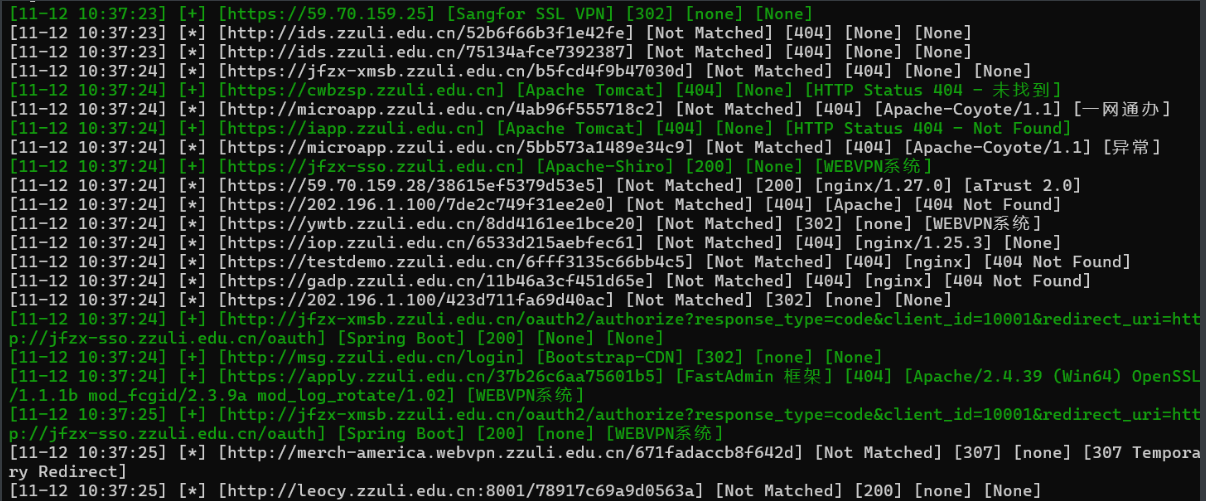
最终配合http/https协议获取最全web资产合集web.txt,一般而言,我们应该会直接进行测活,并重新整理存活的站点测试。但是有时候会遇到一种情况,就是主站点访问为空或者重定向,但是我们添加某个路由之后又能正常访问,这就可能让我们丢失一些可能存在漏洞的目标,所以还有一道工序
Host碰撞 那就是Host碰撞。host碰撞旨在发现隐蔽的边缘资产,原理的话就不过多赘述了
这次目标就不要放在一些过于正常的界面,比如:Centos默认界面、nginx默认界面,还有就是访问不正常的界面,比如:30X、403、404、50X等等。
如果我们的时间多的话,我们就可以把上面web.txt文件中的ip、域名(都带端口)全部 分离出来,可以用这个项目,https://github.com/Secur1ty0/Idregex
问就是好用,而且还可以生成一下fofa、hunter的语法。
如果时间比较紧促,就先可以测活然后再进行host碰撞
web.txt测活选用Tscanplus的内置工具,挺好用的。
再根据上面的小脚本直接分类筛选出不正常 的ip、域名,都要带端口
直接开始host碰撞
1 java -jar HostCollision.jar -ifp ips.txt -hfp hosts.txt
直接上指纹识别
指纹识别 定义
指纹识别就像指纹一样来识别web站点的前端源代码、目录中的信息来识别某个系统的名称、登录框等功能。
意义
用来识别脆弱的易攻破的资产
工具
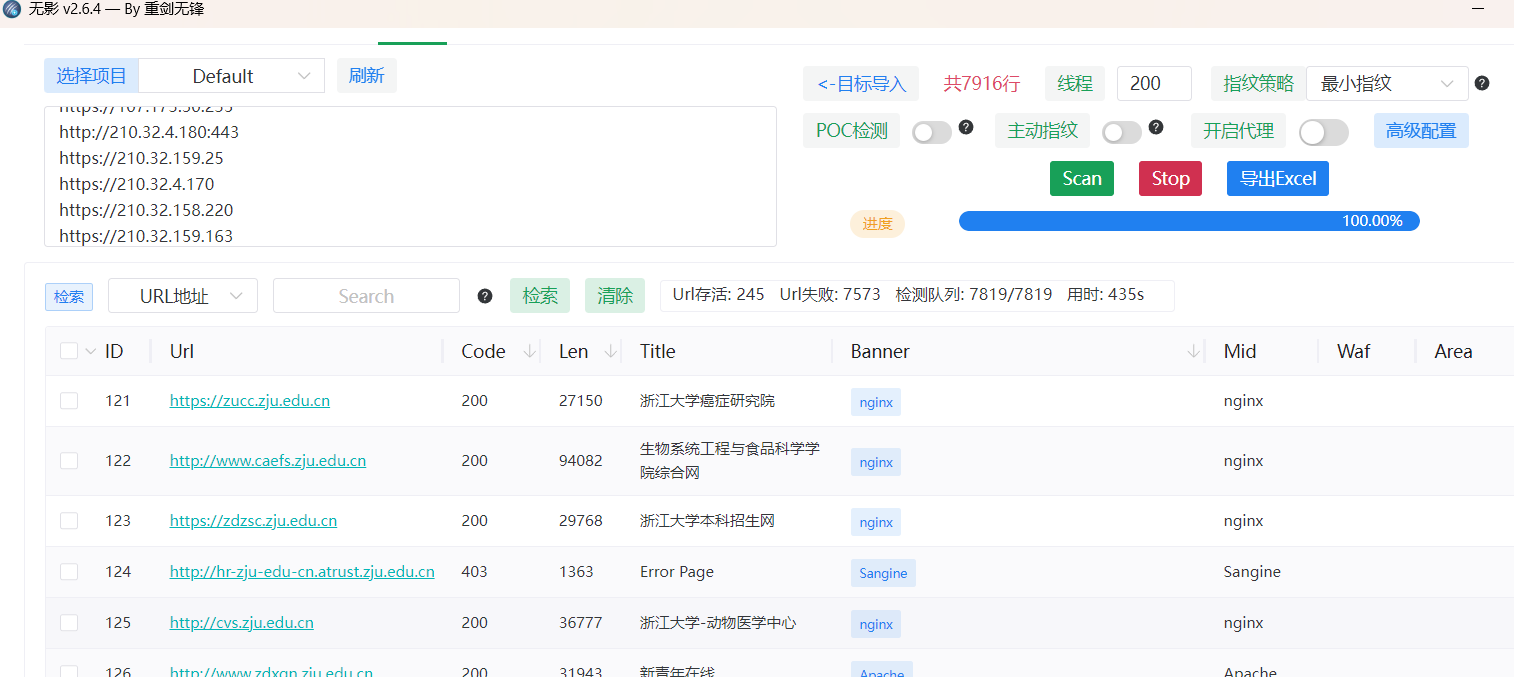
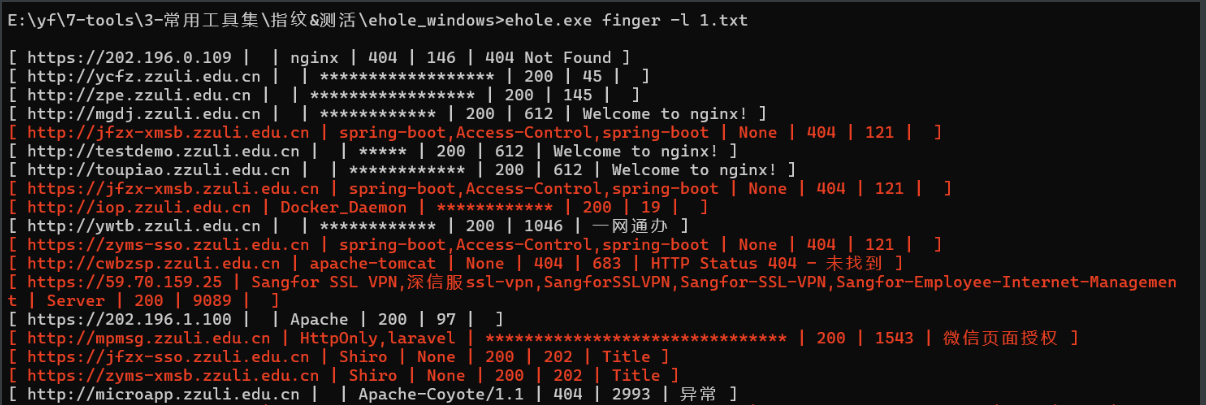
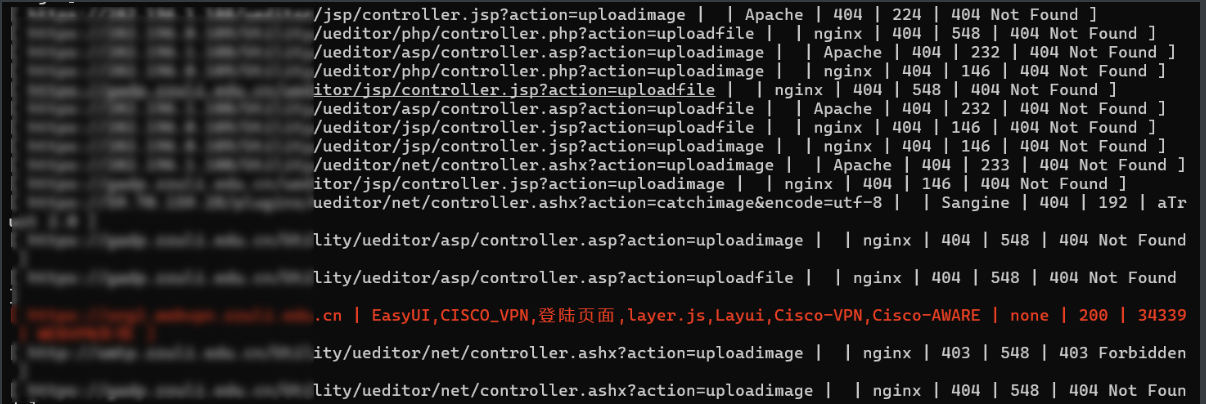
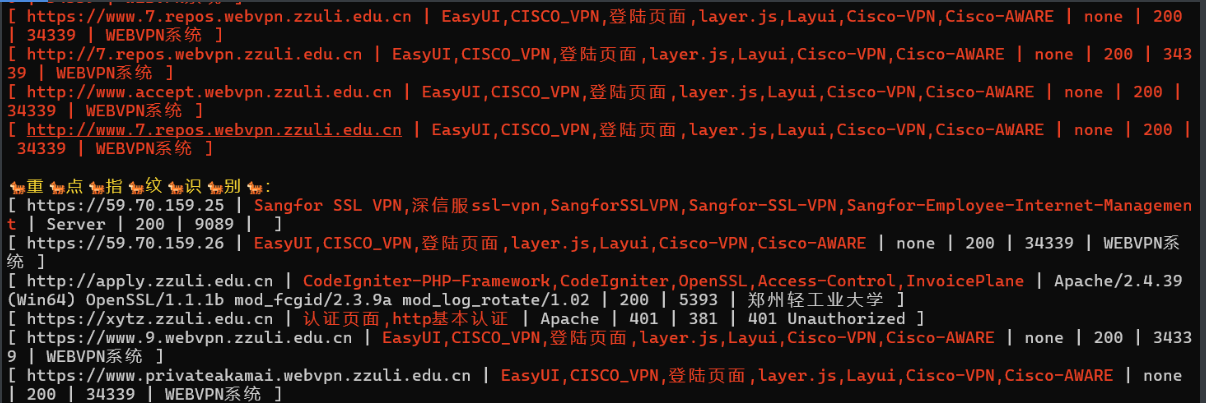
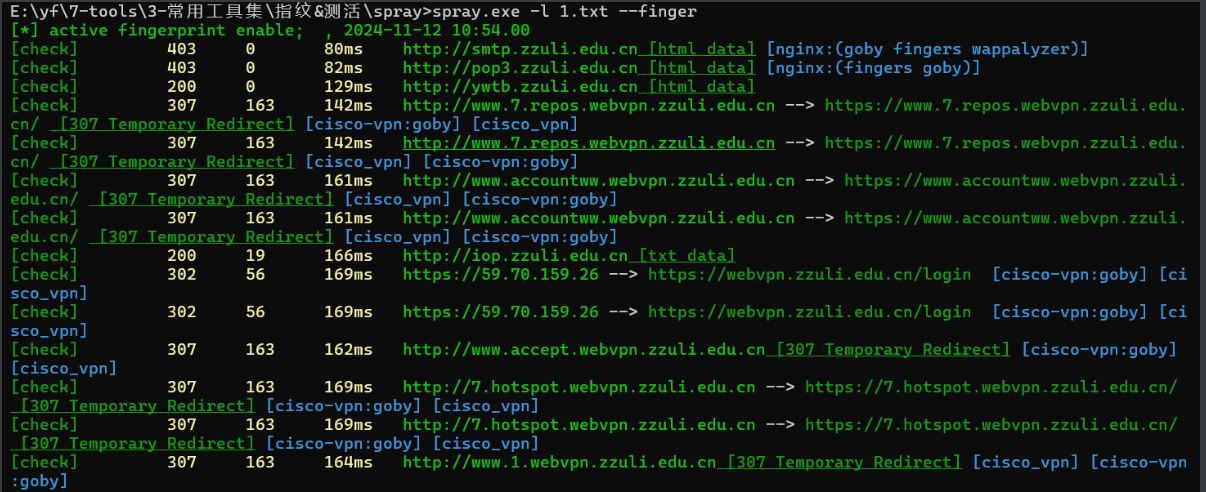
1、Ehole魔改版
针对没什么waf的资产(edusrc还是不适合用)强推,非常的快!同时还会带有对重点目标进行目录侦察的效果(poc.ini中设置),指纹库也比较强,不过可惜的是状态码的颜色看起来差点感觉。
爆破一些敏感路径,但是也有弊端,因为一般而言,网站都有waf,爆破敏感路径可能会被直接封ip,就老实了
2、简单对比一下,其他的指纹识别工具
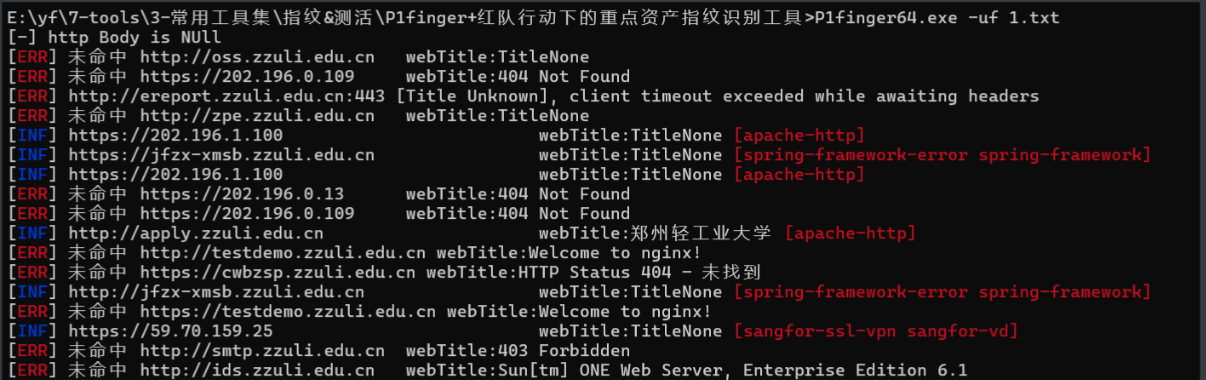
P1finger+红队行动下的重点资产指纹识别工具
感觉一般
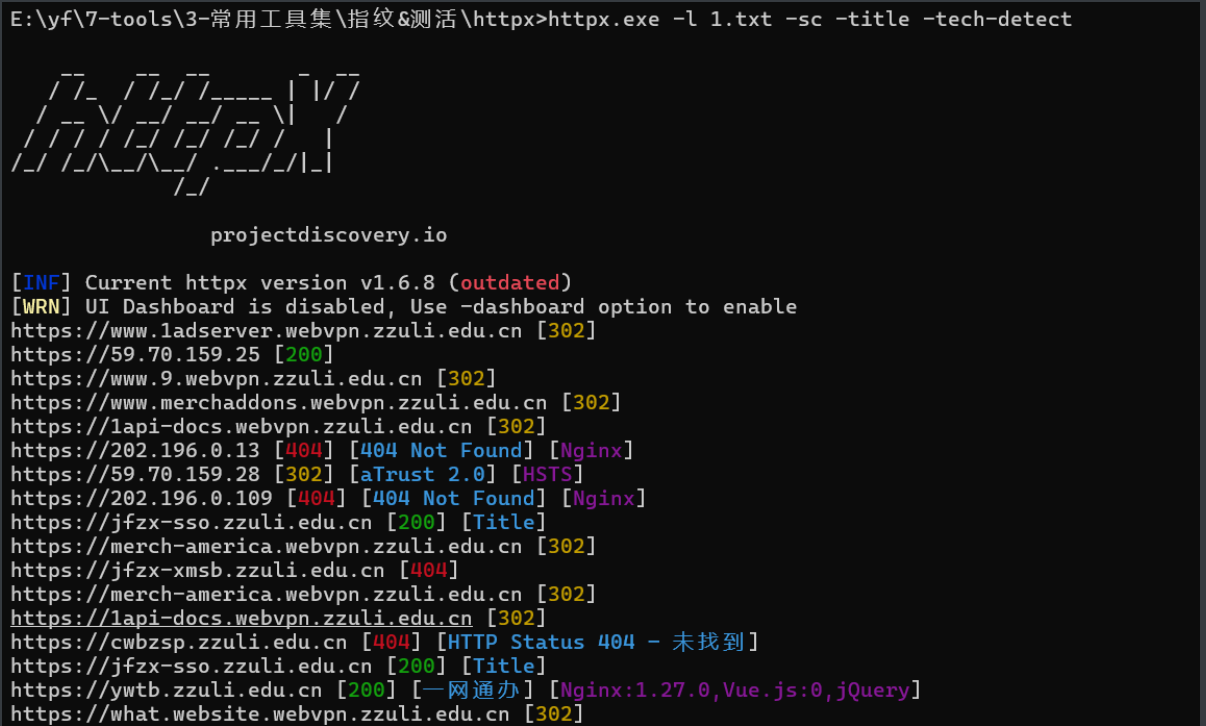
httpx(有计算favicon.icon的功能)(httpx.exe -l 1.txt -sc -title -tech-detect)
展示效果很醒目,但是指纹库感觉一般
hfinger
展示看起来一般,但是指纹库、识别方式较好,用于快速侦察比较脆弱的目标
TigerV1.0(2).2
感觉指纹库和指纹探查一般
Tidefinger
这工具具有端口探测的功能,但是感觉指纹侦察一般
spray
感觉输出不太舒服,但是指纹库还行
综上所述:
对于waf弱的攻防、测试,带有poc检测的神器ehole魔改 ,毋庸置疑
但是对于waf比较强的则可以关闭ehole魔改的POC模块,即可
单个站点收集 主要看能不能找一些敏感文件,方式:google黑语法、github泄露、快照泄露
1、google黑语法:
1 2 3 site:target.com filetype:.doc | .docx | .xls | .xlsx | .ppt | .pptx | .odt | .pdf | .rtf | .sxw | .psw | .csv
不限于此:
Google Dorks 获取漏洞赏金(雨苁):https://www.ddosi.org/dork/
懒人dork: https://iamunixtz.github.io/LazyDork/
特别是在edusrc上用得很频繁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 -----------------------------常常用到的-----------------------------sfz |学号 |xh |登录 |注册 |管理 |平台 |验证码 |账号 |系统 |手册 |默认密码 |初始密码 |password |联系电话 |操作手册 |vpn |名单 body关键词 site:google.com intext:身份证 |sfz |学号 |xh |登录 |注册 |管理 |平台 |验证码 |账号 |系统 |手册 |默认密码 |初始密码 |password |联系电话 |操作手册 |vpn |名单 文件类型(文件类型不支持|,需要拆分出来单独查询) site:google.com filetype:pdf |xls |xlsx |docx |doc |text |ini |mdb |txtasp |php |jsp |do |.action |htmladmin |manage |sysadmin |system |master |admin_login |cms |data |templates |indexupload |uploadfile |ewebeditor |kindediter |Ueditor |file |choosefile"parent directory" "审计报告" "身份证" "SFZ" "财务报告" "身份证" "SFZ" "科技奖" "身份证" "SFZ" "发明专利" "身份证" "SFZ" "财务报告" "身份证" "SFZ" "无犯罪记录" "身份证" "SFZ" "特发此证" "身份证" "SFZ" "出版合同" "身份证" "SFZ" "甲方代表" "身份证" "SFZ" "乙方代表" "身份证" "SFZ" "籍贯" "身份证" "SFZ" "汉族" "身份证" "SFZ" "职称" "身份证" "SFZ" "google.com" smtp password"google.com" smtp @126.com "google.com" String password smtp"google.com" root password"google.com" sa password"google.com" User ID='sa';Password"google.com" svn"google.com" svn password"google.com" svn username"google.com" svn username password"google.com" inurl:sql"google.com" password"google.com" ftp ftppassword"google.com" 密码"google.com" 内部
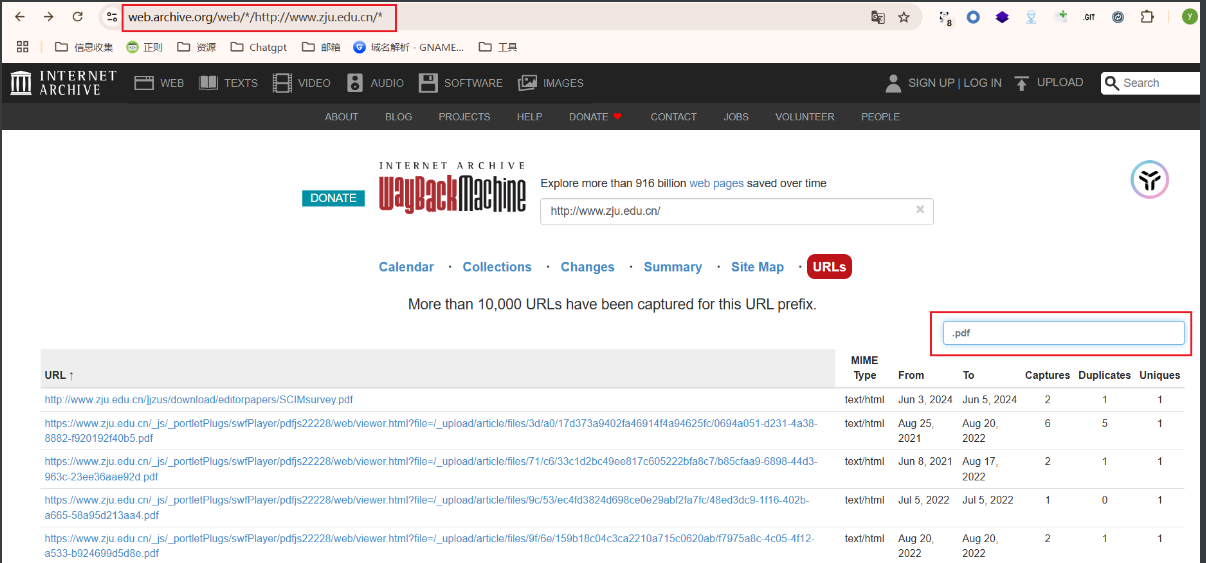
2、网站时光机:
1 2 3 4 5 找一些路由,替换参数url为网址即可//web.archive.org/cdx/search ?collapse=urlkey&fl=original&limit=10000000000000000&matchType=domain&output=text&url=1.txt 、.xlsx 、.pdf... //web.archive.org/
3、github泄露:(在挖掘企业时有时候有奇效)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 in :name baidu #标题搜索含有关键字baiduin :descripton baidu #仓库描述搜索含有关键字in :readme baidu #Readme文件搜素含有关键字stars :>3000 baidu #stars数量大于3000 的搜索关键字stars :1000 ..3000 baidu #stars数量大于1000 小于3000 的搜索关键字forks :>1000 baidu #forks数量大于1000 的搜索关键字forks :1000 ..3000 baidu #forks数量大于1000 小于3000 的搜索关键字size :>=5000 baidu #指定仓库大于5000 k(5 M)的搜索关键字pushed :>2019 -02 -12 baidu #发布时间大于2019 -02 -12 的搜索关键字created :>2019 -02 -12 baidu #创建时间大于2019 -02 -12 的搜索关键字user :name #用户名搜素license :apache-2 .0 baidu #明确仓库的 LICENSE 搜索关键字language :java baidu #在java语言的代码中搜索关键字user :baidu in:name baidu #组合搜索,用户名baidu的标题含有baidu的等等
3、目录扫描
这个目录扫描并非全是纯跑目录字典,更别说那些waf比较强的站点,你更不可能全去爆破,最重要的点还有有想象力,根据站点已暴露的目录,去猜其他可能的站点,例如:有/login目录,那也有可能有一个/register站点。
4、中间件
收集方式
请求头、指纹识别暴露 、wappalyzer 、根据报错信息判断 、根据默认页面判断。
5、开发语言
查看网站包
查看站点文件后缀
搜索引擎:site:<域名> <语言>
6、源码查找
可以直接指纹识别CMS、寻找网站框架,根据网站的一些图标、logo、关键字,还有一些特殊的目录,甚至是f12源代码中的作者泄露去寻找源码。
源码可以在github、fofa、搜索引擎、专属源码站点上去寻找
Edusrc信息收集 信息收集重心:学号、身份证、工号、电话号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 site :xx.edu.cn filetype :pdf 身份证 学号 工号 初始密码site :xx.edu.cn filetype :docx 身份证 学号 工号site :xx.edu.cn filetype :xlsx 身份证 学号 工号"注册" || "系统" || "登录" || "后台" || "管理" ) && org="China Education and Research Network Center" domain ="xxx.edu.cn" || cert="xxx.edu.cn" || cert="xx大学" ....1 、可以去当地的教育局查看是否有敏感信息。2 、直接去社交平台找泄露3 、社工哥3.1 、直接加qq群,你知道的呀!3.2 、可以去找一些学校可能存在什么失物招领的平台,直接打call,你知道的呀!
还有就是一些学校肯定不止一个域名,他还会存在其他分支,虽然上面的fofa语法也可以检索一些出来,但并不完全
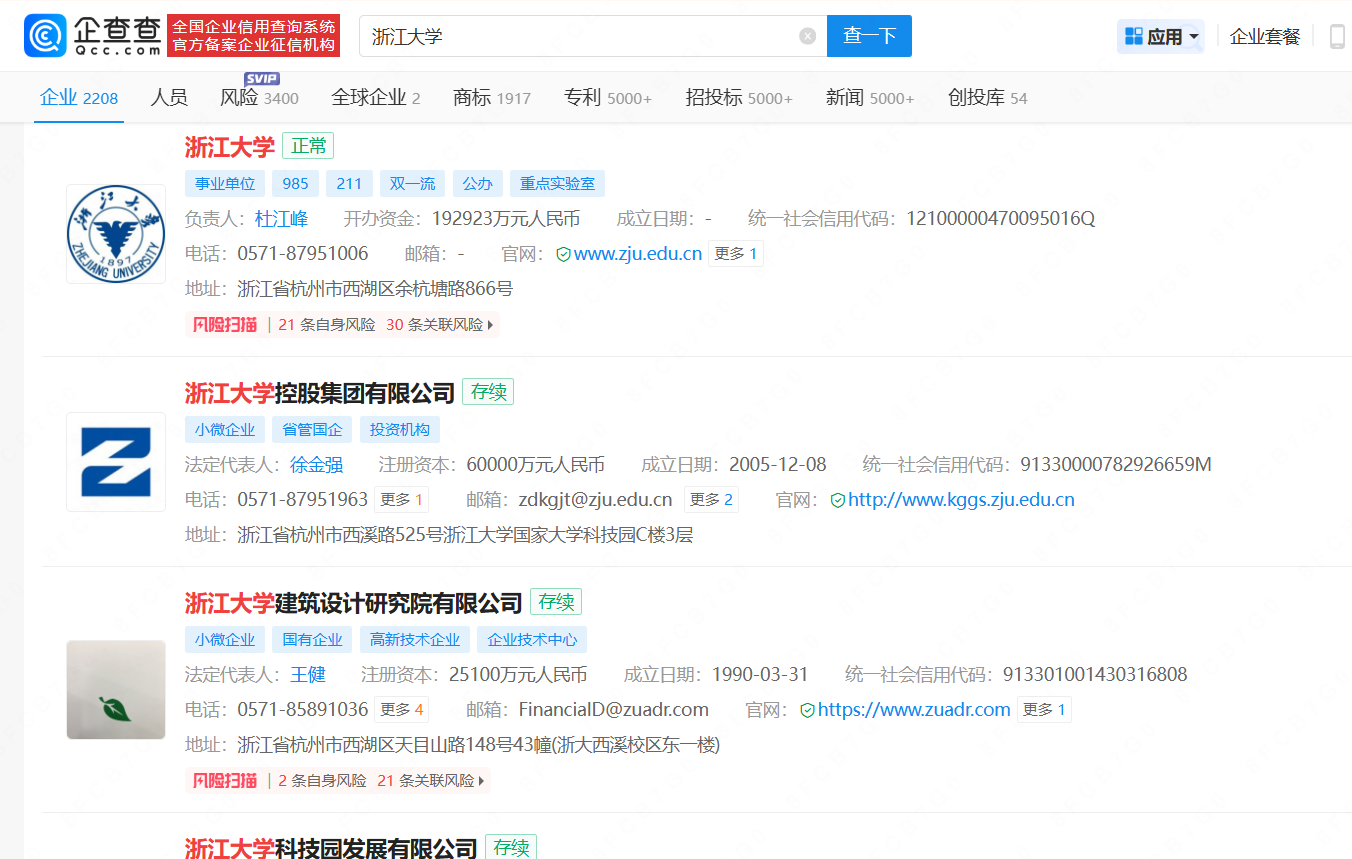
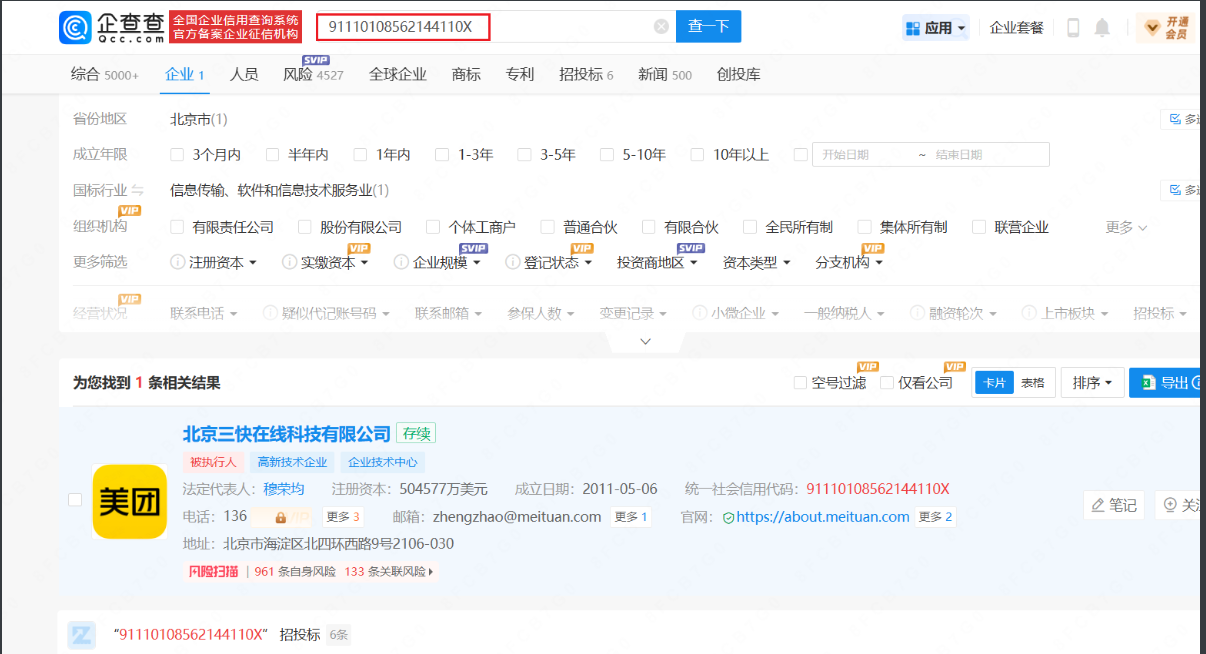
以浙江大学为例,我们可以在企查查上去看
这些资产都隶属浙江大学,都是可以收集的,这里可以参考之前子公司收集的思路结局。拿到了主域名,再参考子域名收集。
供应链信息收集 实在无法破局,采用供应链(多在edu、企业也有)
基本阐述
1 2 3 4 5 6 7 8 9 10 11 12 13 1、确定供应商**招标** 公开网(学校)
结语:在复杂环境下,效率偏低
小程序&公众号 针对一些web打不动的资产,说不定其小程序公众号会有洞可以寻,所以小程序公众号的信息收集必不可少
小程序&公众号定位 1、微信搜索
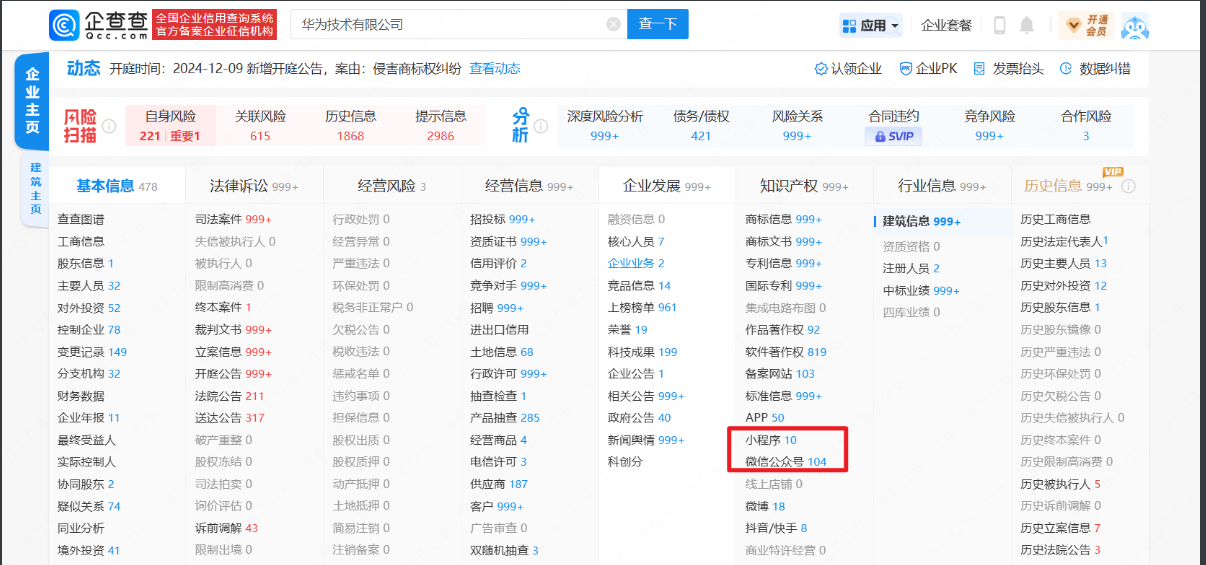
根据资产名称在微信中搜索,以”华为”为例,其公司全称为”华为技术有限公司”。
企查查
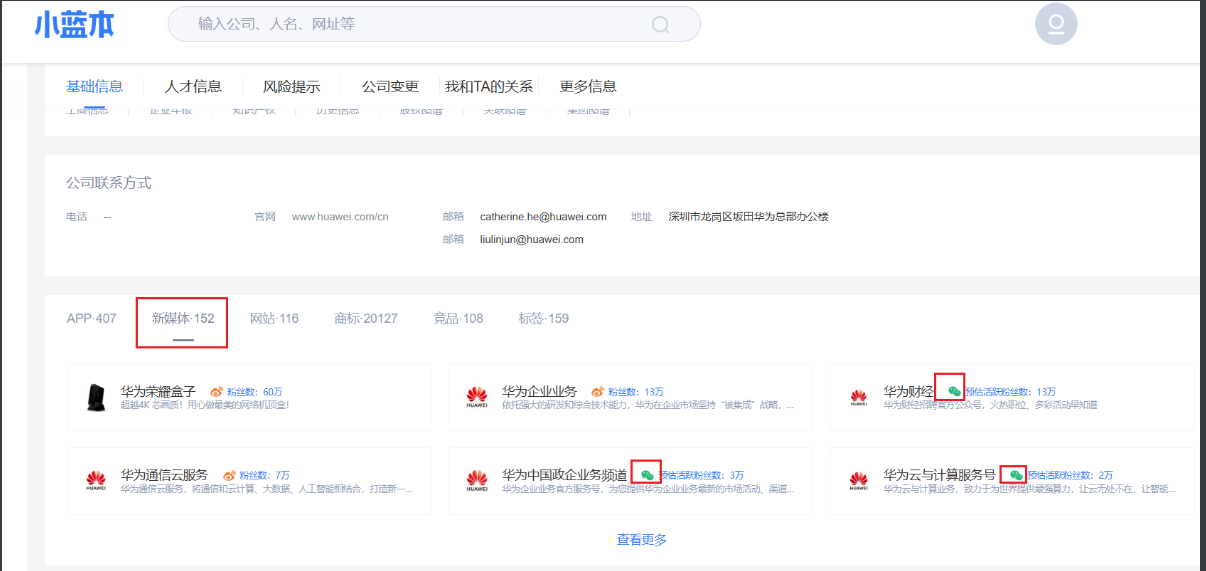
小蓝本
公众号&小程序如何信息收集 主要在模拟器、手机端 上实现,不知道为什么,一些信息不能直接在pc端微信上获取,下述是在模拟器的收集过程
1、小程序
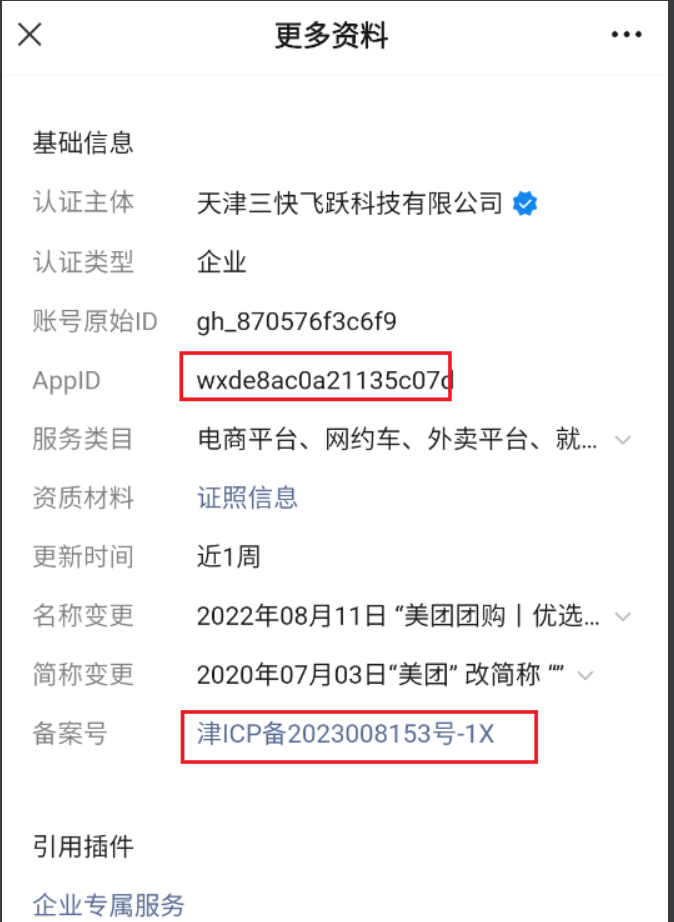
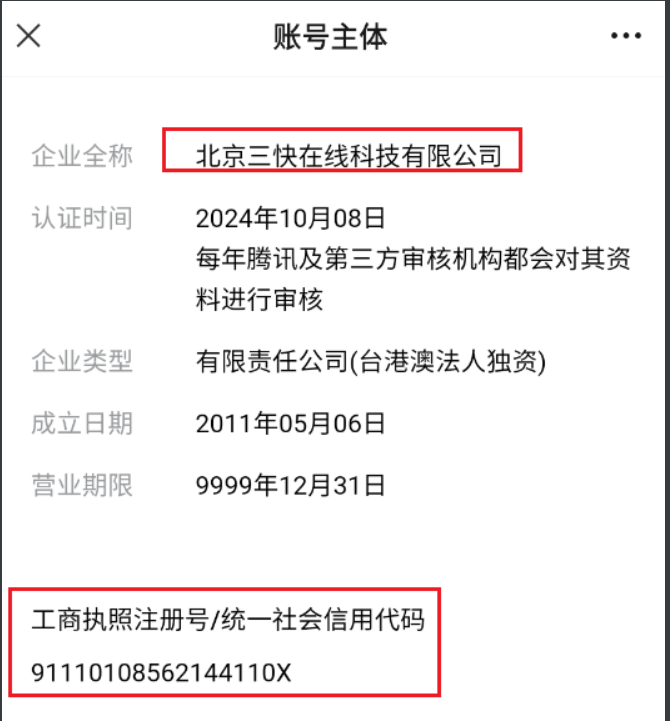
对于一些大厂的小程序公众号可能含有上述三个信息,不过最常见的就是”更多资料“
可获取appid、备案号
根据备案号也可以反查其他小程序
在pc端我却是没有找到收集路径,还希望佬们指点指点。
2、公众号
再在企查查等上面去查,获取更多的小程序、公众号
3、抓包方面
抓包测试方面也一起说了,不知道为什么我在模拟器(夜神)搜公众号,总是没有结果,所以我直接在pc端进行抓包测试了,虽然在pc端无法信息收集,但是抓包测试绝对是一把好手!并且我做了对比,pc端和手机端的公众号、小程序的数目没有差别(反正我没有看到差别)。
抓包主要使用:burp+proxifier+pc端微信即可
参考:https://mp.weixin.qq.com/s/_x8c88RQ8zoeEqRVnvBPtg
小程序逆向 获取接口+资产信息
工具:
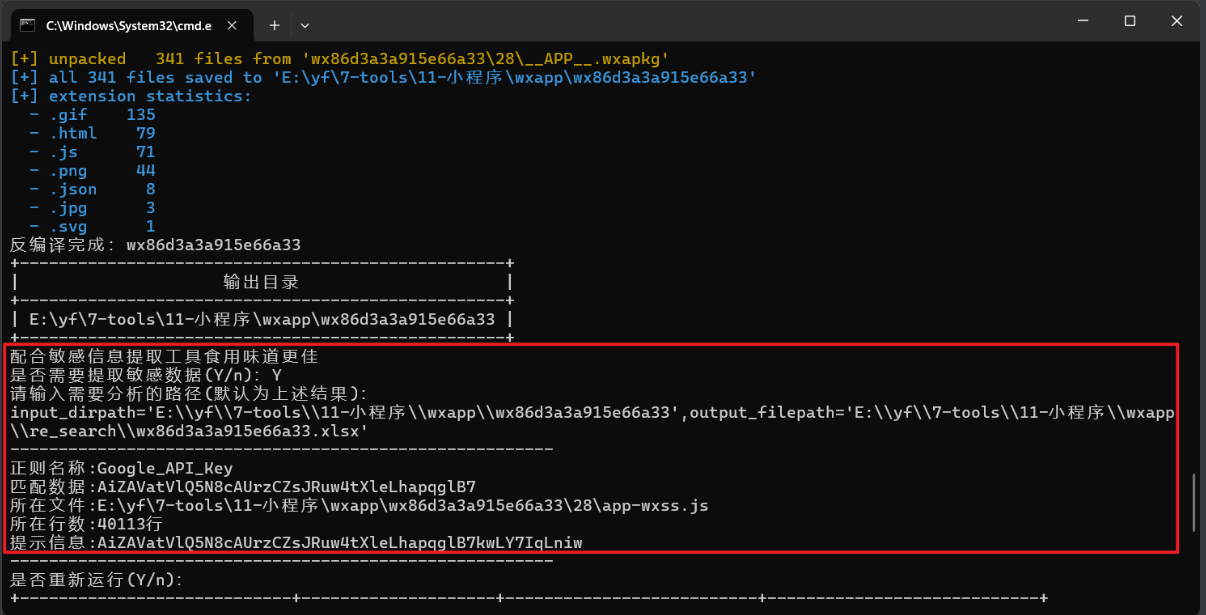
1、https://github.com/Siffre/wxappUnpacker
可以关注其中有没有硬编码的密码、企业微信key、公众号key、AK/SK等等,此外app.json里一般都写好了小程序要调用的接口路径,按照常规思路利用攻击即可!
2、pc端小程序目录逆向
3、unveilr逆向
测试方向:逻辑漏洞、文件上传(头像处、身份证上传)、越权
挖掘方法也比较简单,比如在有验证下一步的时候,抓包,查看返回包响应码,尝试修改响应码,或者其他你认为影响返回状态的值(具体情况具体分析),尝试能不能绕过。举个例子,比方说输入验证码,我们先输入正确的验证码,查看返回包特征和状态,然后输入一个错误的验证码,把刚刚正确的返回包特征尝试替换,看看能不能绕过
4、逆向+敏感信息查找
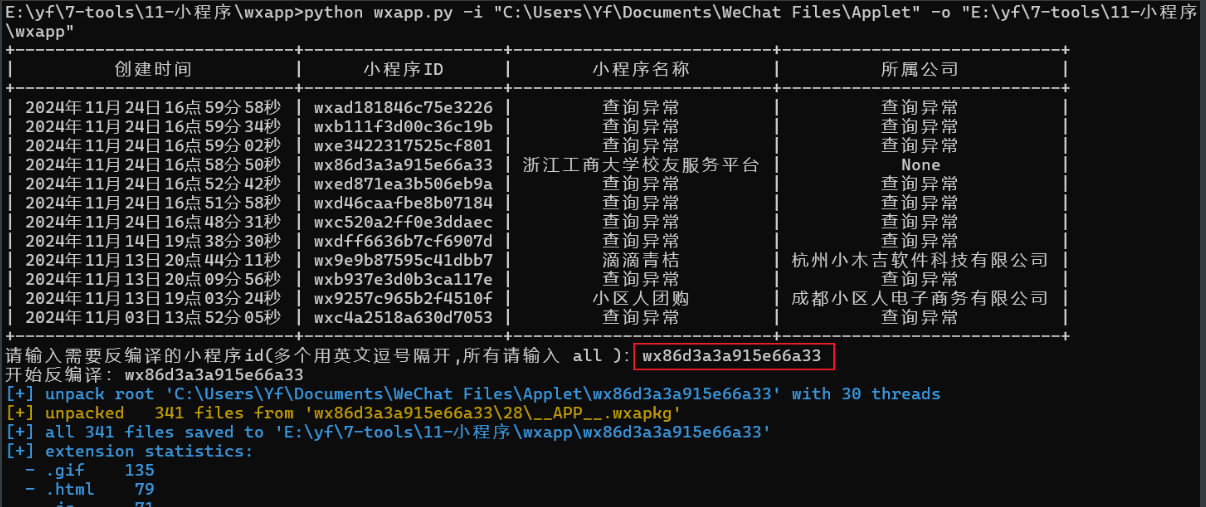
Wxapp
F12调试小程序 开小号 调试,可能会被封!
https://github.com/JaveleyQAQ/WeChatOpenDevTools-Python
这个工具的用法也是很简单,我们进去微信之后(最好用小号避免封号),直接运行python main.py -x
然后进入小程序
即可调试
apk信息收集 1、利用工具APPinfoScanner
通常场景下我们扫的只有目标APK文件,这里直接用第一条命令
python app.py android -i 123.apk
结果如下
1 2 3 4 5 扫描ios的ipa文件、machine-o文件.py ios -i xxx.ipa .py web -i www.xxx .com
app测试得比较少,不太会信息收集,只能当脚本小子了,惭愧惭愧!
国外站点信息收集 国内用到企查查、天眼查、小蓝本这些,去构建“股权树”,梳理公司
国外就可以用到以下网站
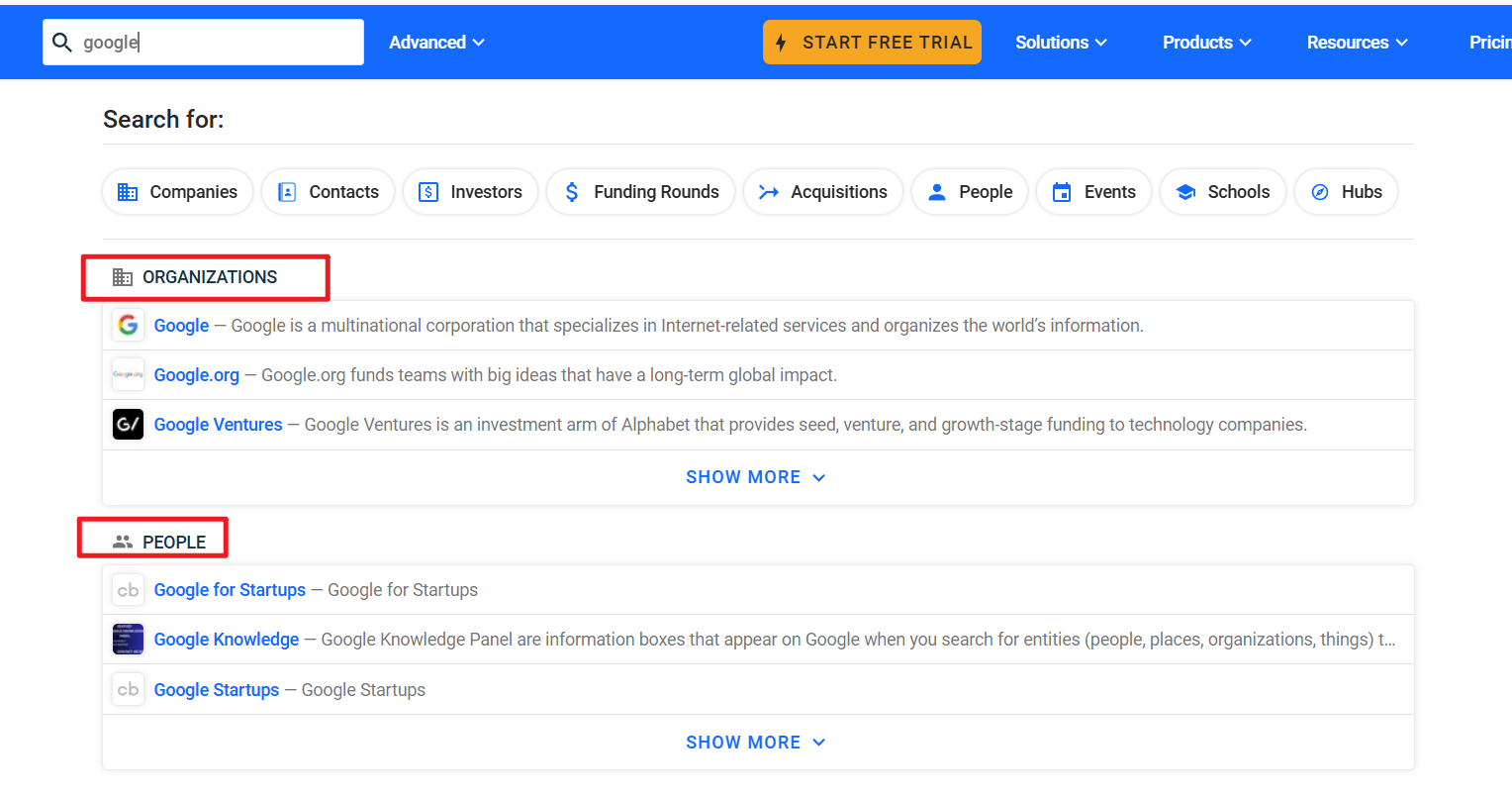
https://www.crunchbase.com
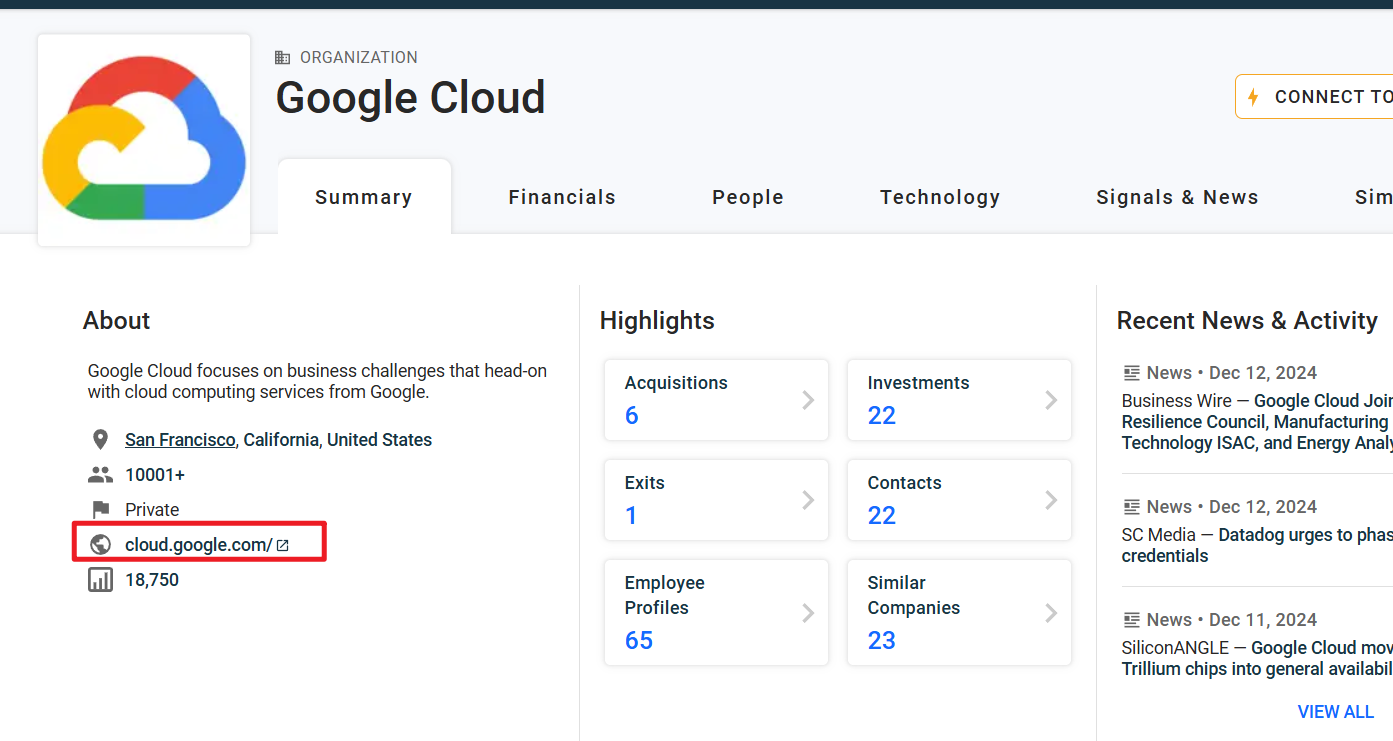
以google为例,下面的ORG为相关组织,就是公司,People就是法定代表人
随便点一个组织点进去,下面就是资产入口
使用fofa结合crt证书收集,也很不多,这个主要是用来收集主域名,其他子域名,可以采上述的子域名收集,不过使用工具时,最好搭个代理,这样收集得更多。
偏僻子域名 https://otx.alienvault.com/api/v1/indicators/domain/baidu.com/url_list?limit=100&page=1
试试就知道了,想查什么域名,就替换baidu.com这一项就行,最后面的
政府信息收集 说到政府机构的信息收集,感觉跟企业的话,主要是在获取主域名的时候有点区别,主域名不能再依靠企查查、天眼查了。
提供以下两种方式去收集
1、搜索引擎
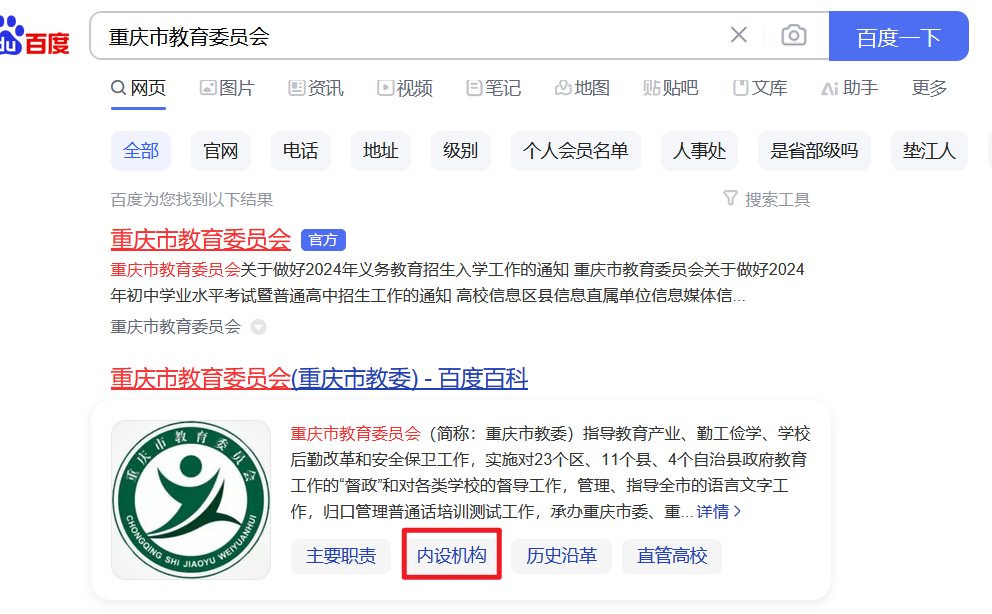
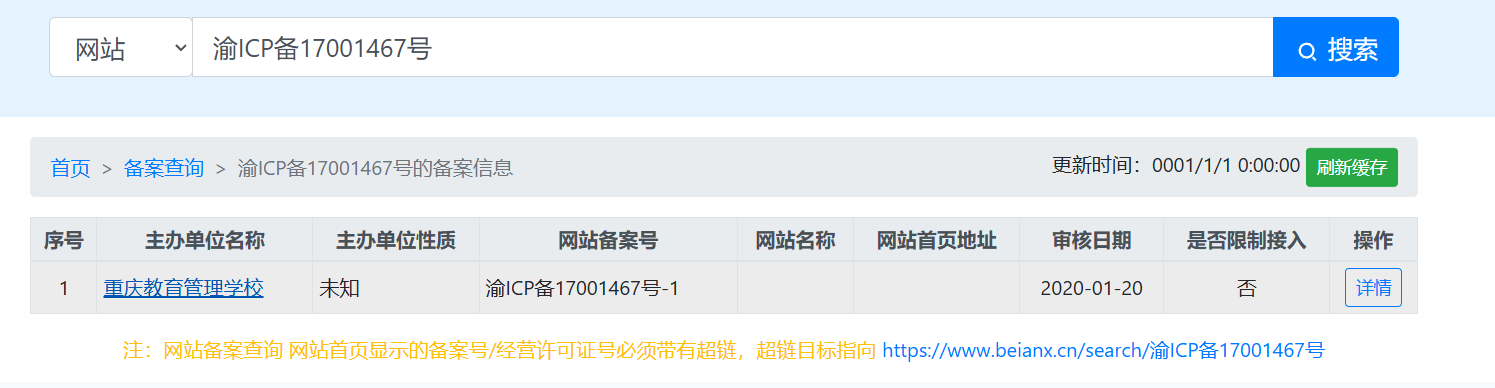
以重庆教育委员会为例,我们直接用百度词条,搜“重庆市教育委员会”或者“重庆市教育委员会 百度百科”
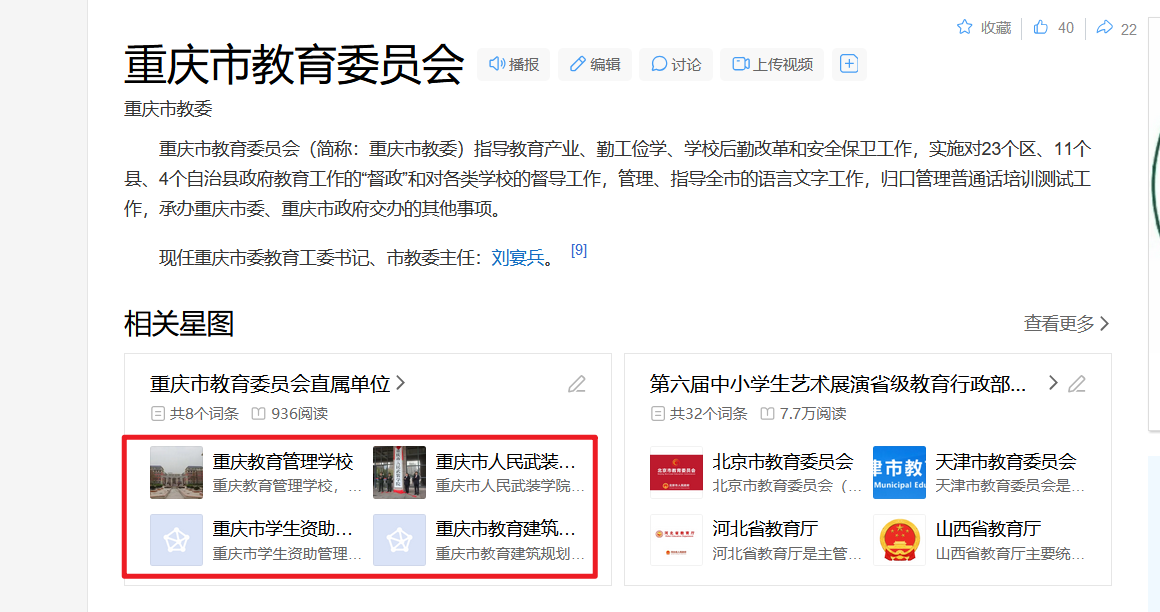
直接进点入内设机构,就可以看到相关单位
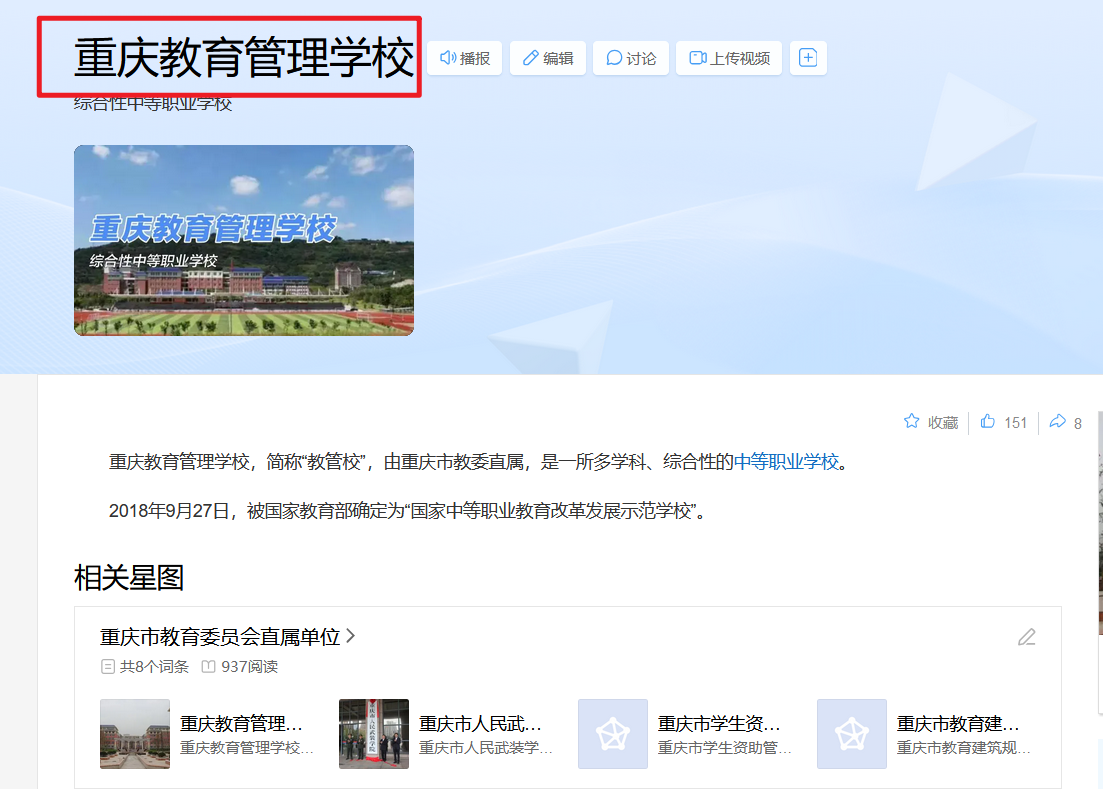
以第一个管理学校为例
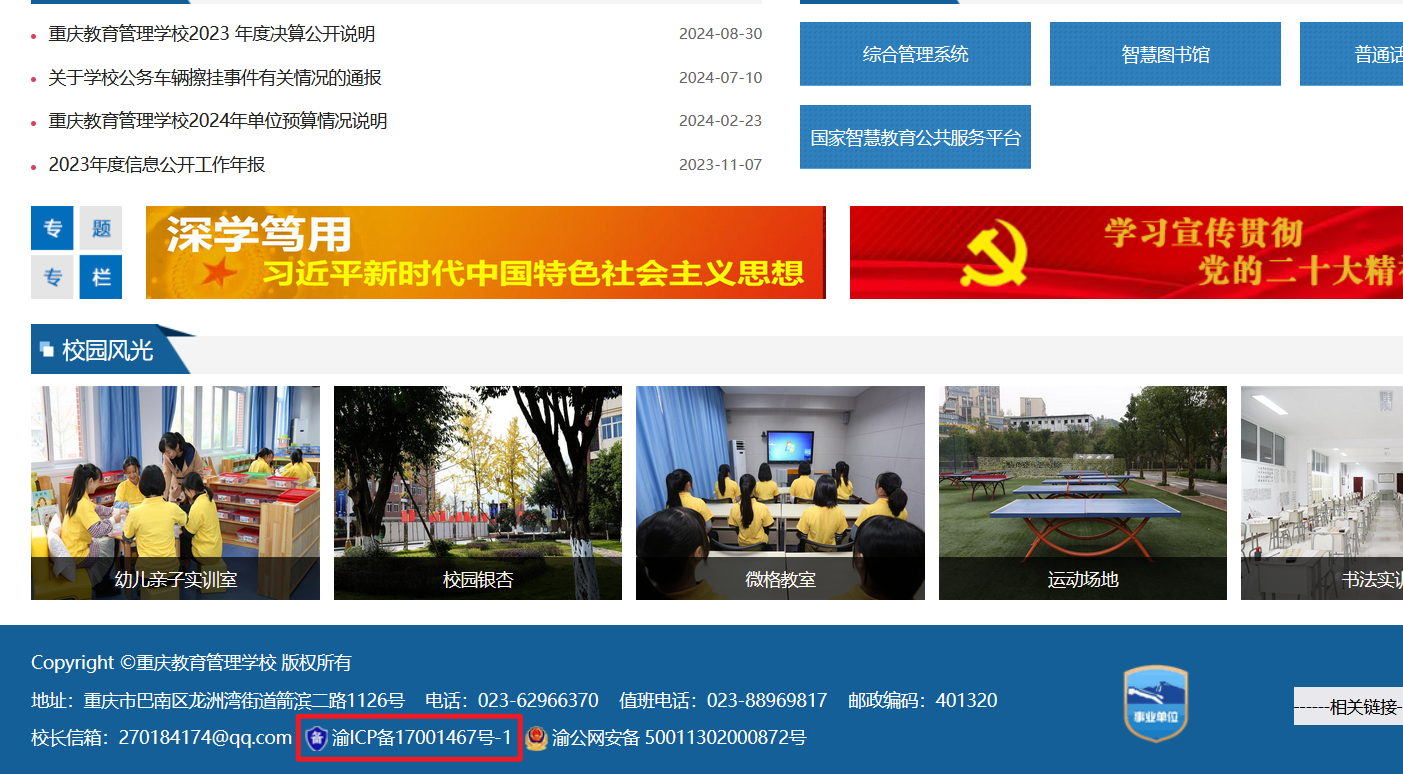
直接再搜他,找到他的官网,看备案号
再到ICP备案
就差不多了。
此外一个小tips,厅级单位打不下来,可以尝试打局级单位,尤其是省会的局级单位,内网有很大可能是通的,可以从下往上打。
自动化信息收集 谈到自动化信息收集,肯定离不开ARL灯塔,这玩意是真好用,基础指纹识别、基础数据包请求响应、站点截图、泄露扫描、Host碰撞、WIH调用(在JS中收集域名,AK/SK等信息)。不过还是需要自己通过收集主域名。
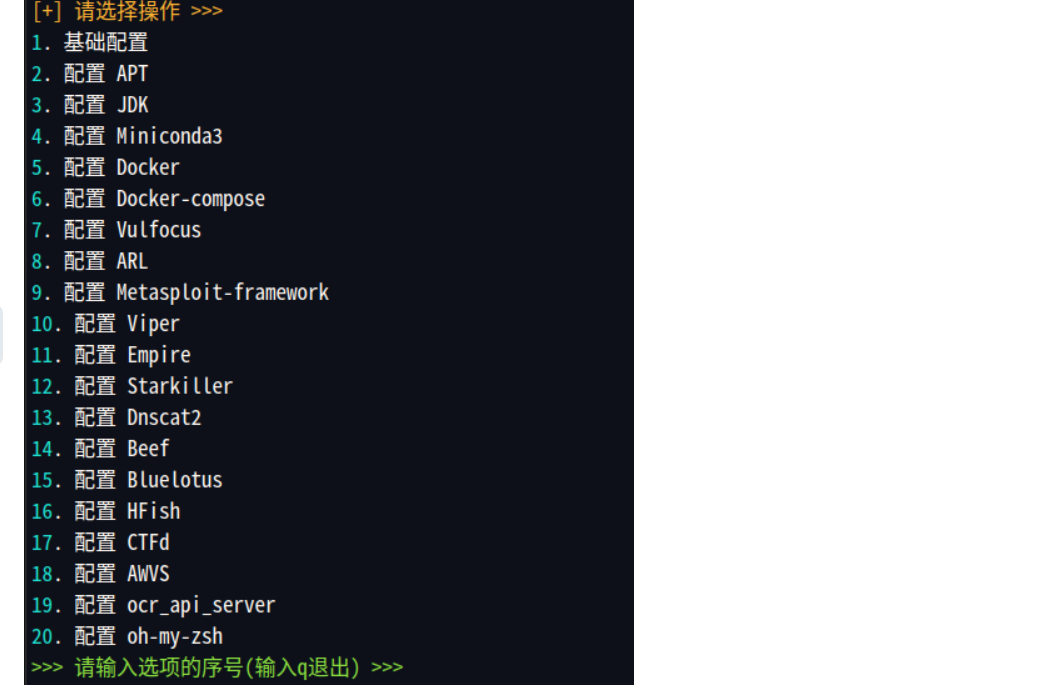
这些都还不错,还可以扩展一点。我这是用docker安装的ARL,有时候朋友们在安装的时候,可能就会因为docker的一些报错整破防了,这里推荐很不错的脚本,里面配备着很多脚本的安装,简直一绝
项目地址:https://gitee.com/yijingsec/LinuxEnvConfig
然后就是一些基础配置了,直接打开config-docker.yaml,直接配置fofa、hunter..的API,或有禁用的域名也改一改。
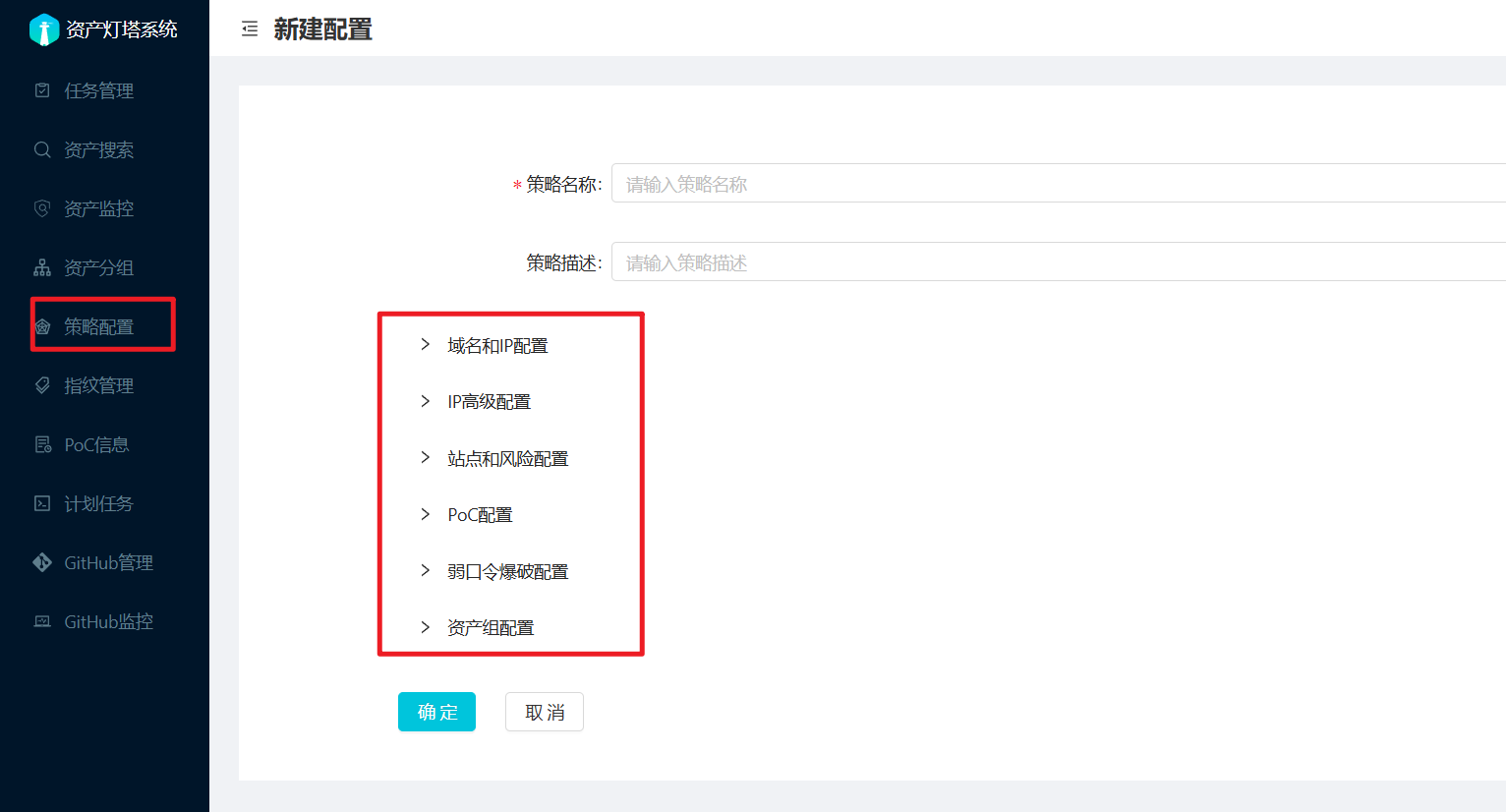
然后再策略配置的这一块,也可以配置相关的信息收集
配置完直接梭哈就完事了。
然后就是水泽,
邮箱搜集 项目开始客户是提供了邮箱地址作为报告的提交地址的,首字母大写+名@xxx的格式,和许多企业的命名规则一样。
google语法:intext:@xxx //来获取邮箱
src快速收集 1、根域名
src公告+企查查(看公告,有些企业会注明,不收子公司)+小蓝本+爱企查
批量操作
以小蓝本为例,我们看到的页面如下
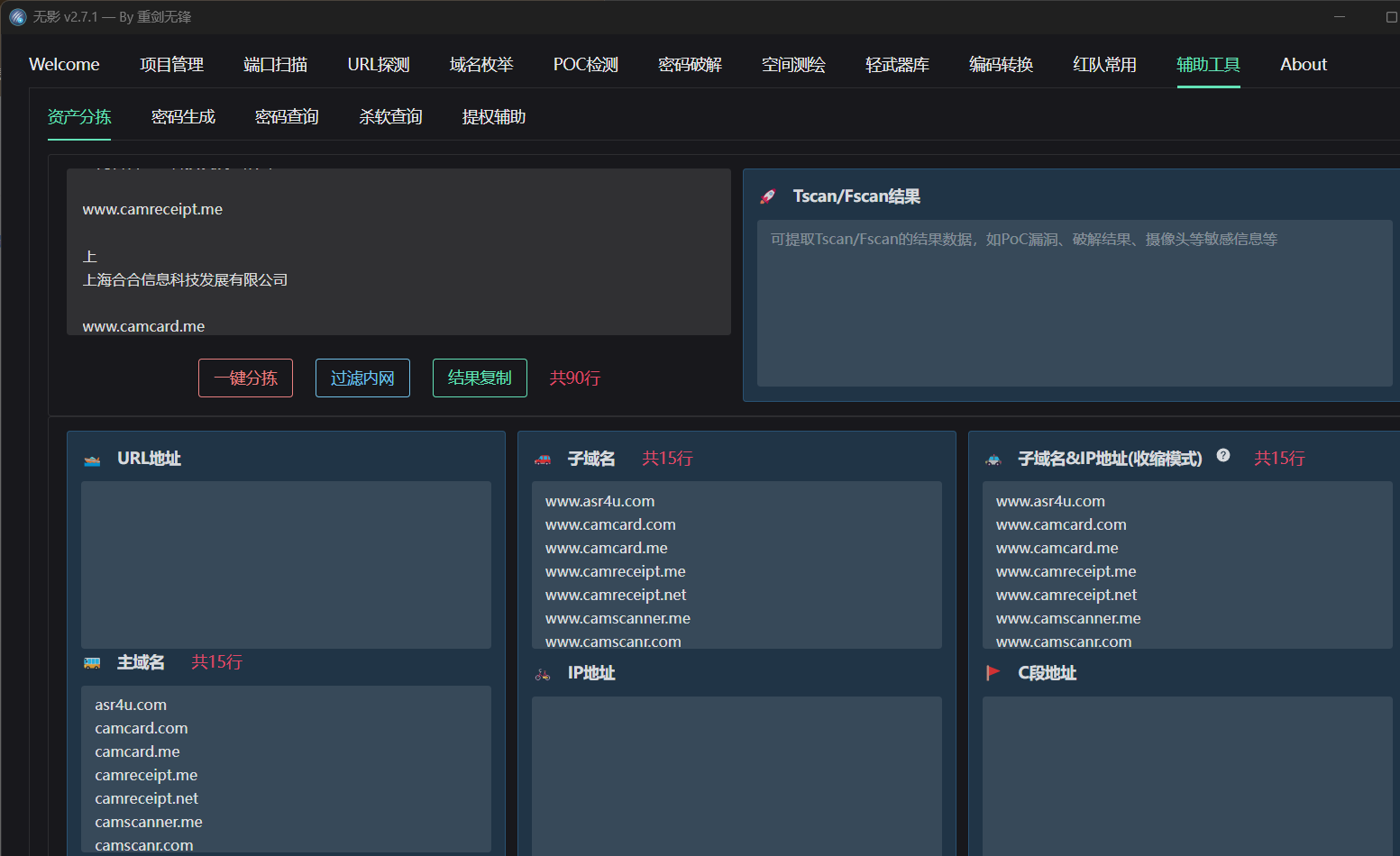
不太可能一个一个复制粘贴,虽然也可以写一个正则,但是有现成的肯定用现成的,这个推荐一个工具Tscanplus
直接全选上面的内容
然后粘贴到Tscanplus的资产分拣处
2、子域名
ARL+oneforall+fofa+hunter+钟馗之眼+水泽
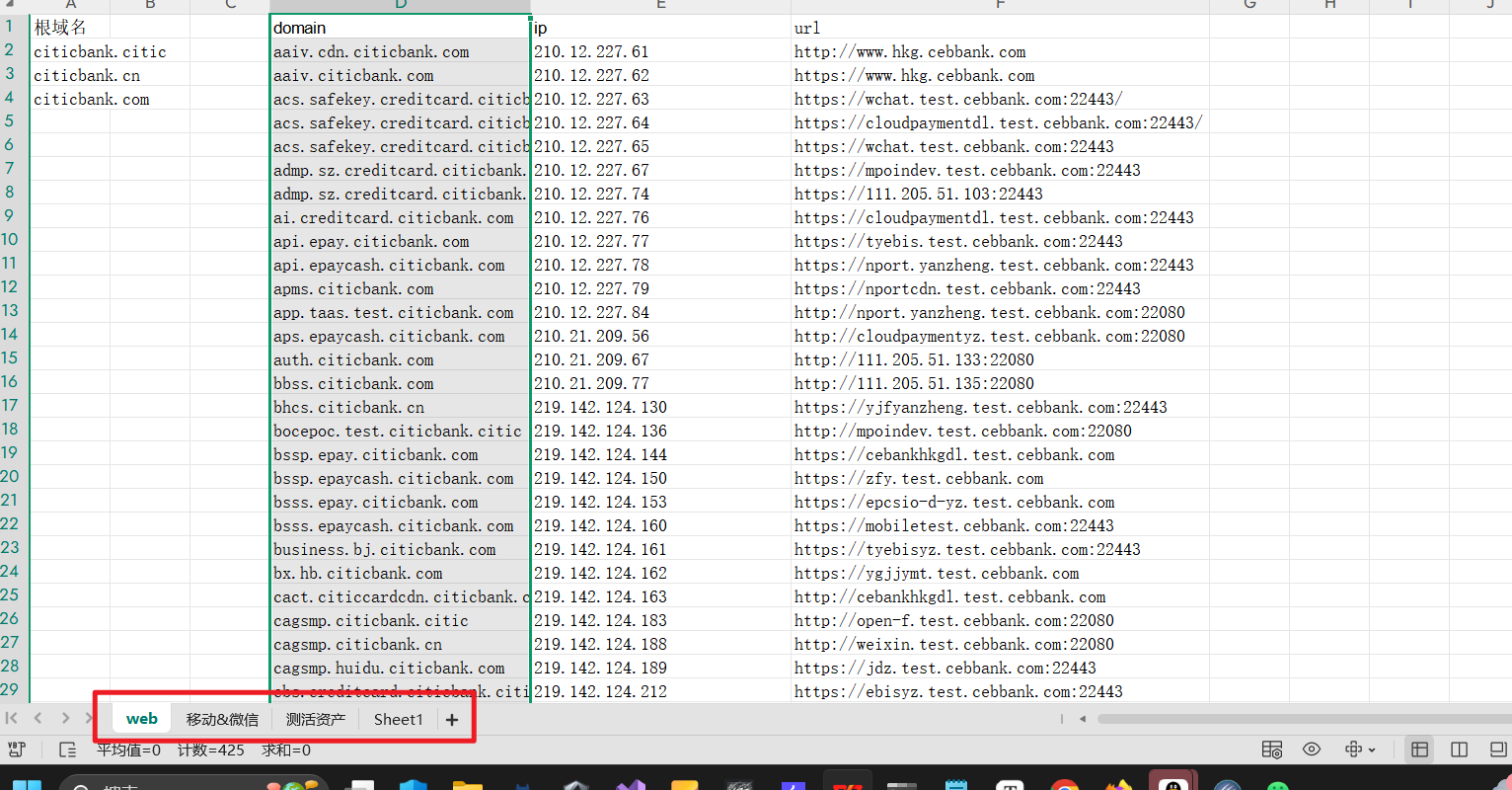
最终会得到批量的子域名、ip、url
然后直接新建一个excel文件,用于资产整理,分为web、小程序、App、整理测活资产
3、资产筛选
资产筛选是为了让我们能够的更快的入手,这也是提高我们漏洞挖掘成功率的关键因素,其次传统的指纹识别,在目前的src漏洞挖掘来看,已经不太实用了,所以我们只需要简单测活后再筛选就行了
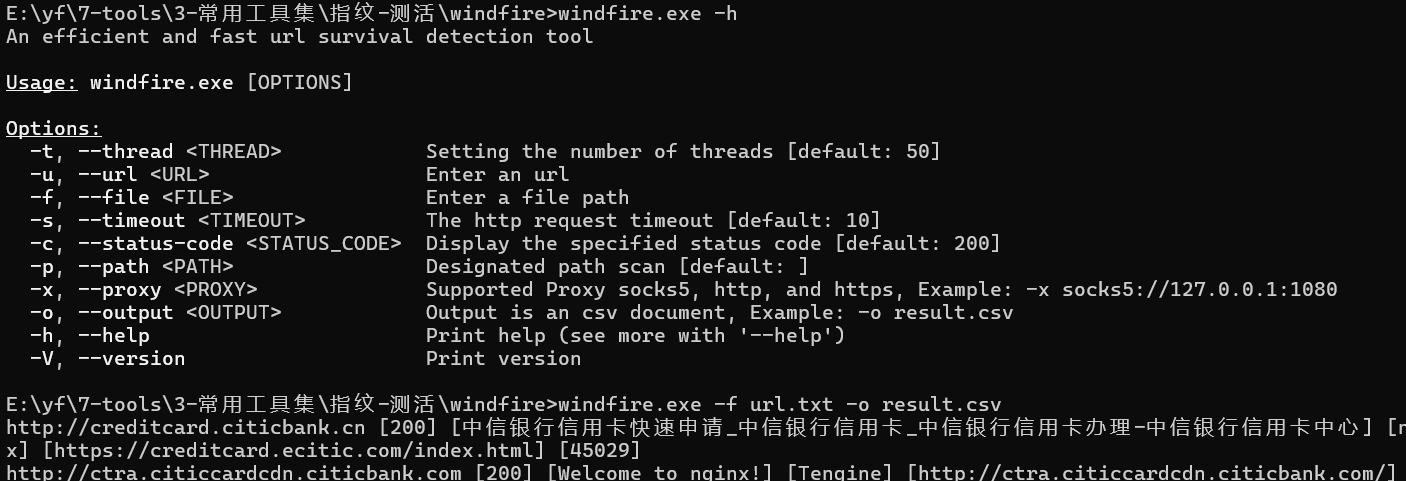
此处推荐一个快速测活的工具
https://github.com/muddlelife/windfire
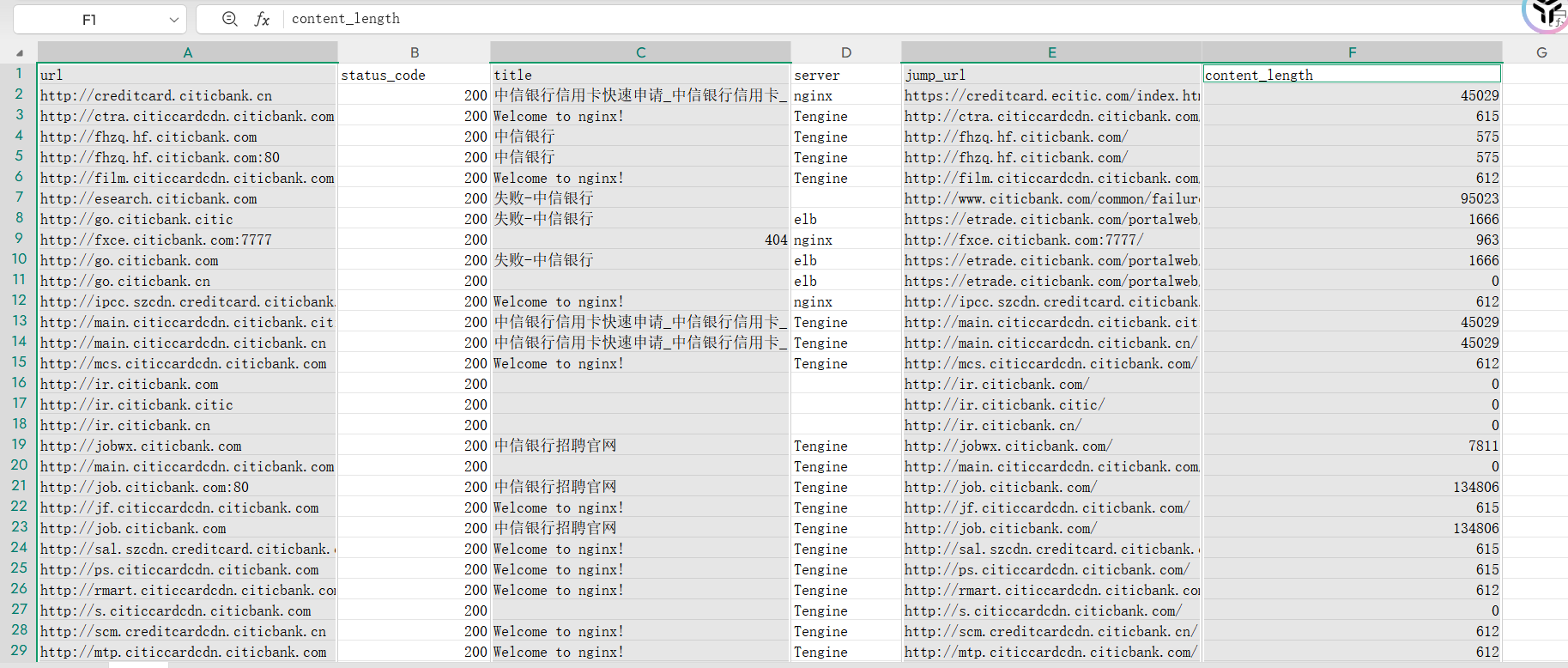
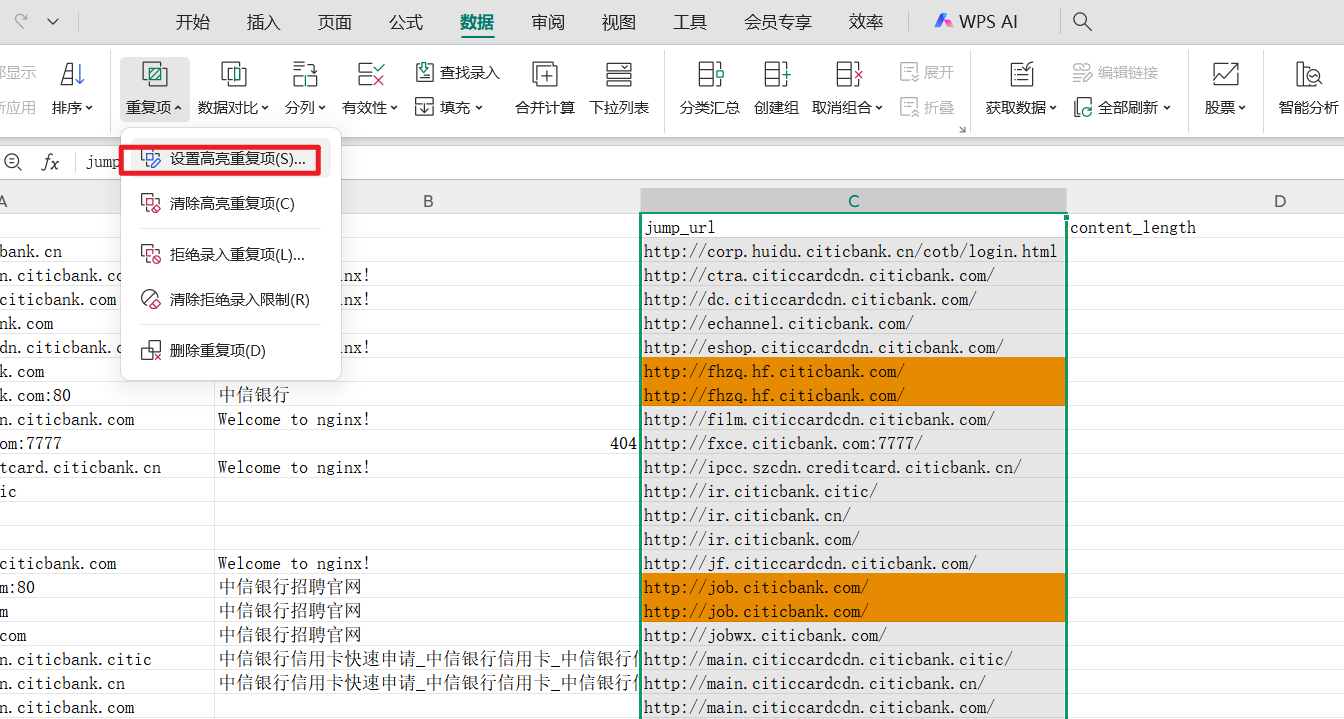
这里推荐筛选200状态码,不过这是为了快速上手,想要深入挖掘,只需要把4xx的状态码筛选掉就可以了。打印结果就像这个样子
此时我们可以把返回长度比较短的,返回长度一样的去重一下,让我们不用花费时精力再去看资产。还是可以对jump_url栏进行排序后,再设置重复高亮
得到我们的最终测试目标,也可以边测试边标注。
CNVD快速锁定资产 简单收集 这个收集方法符合突然有点兴致想挖cnvd的师傅,因为我就是,哈哈哈
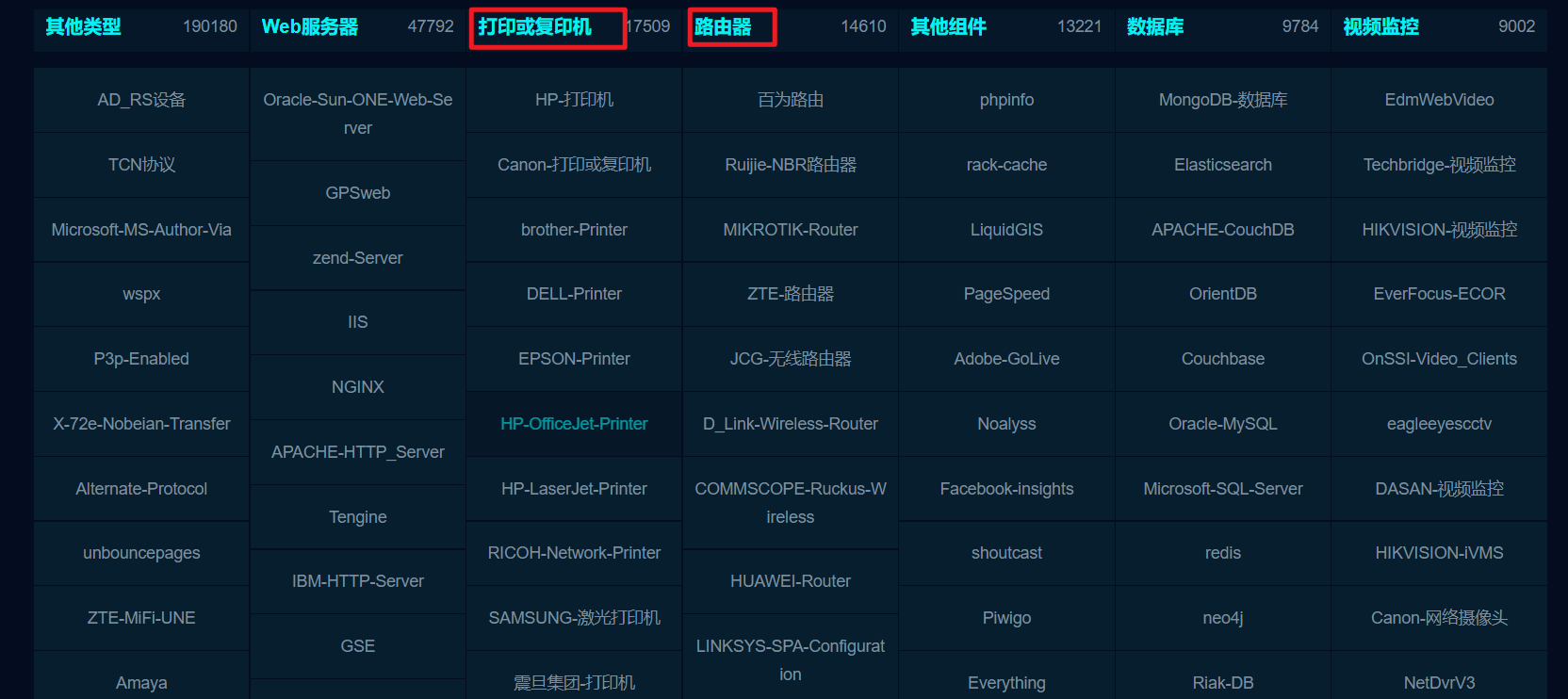
献上万能的fofa
里面存放着一些设备的指纹,可以尝试挖掘打印机、复印机、路由器摄像头弱口令、未授权啥的
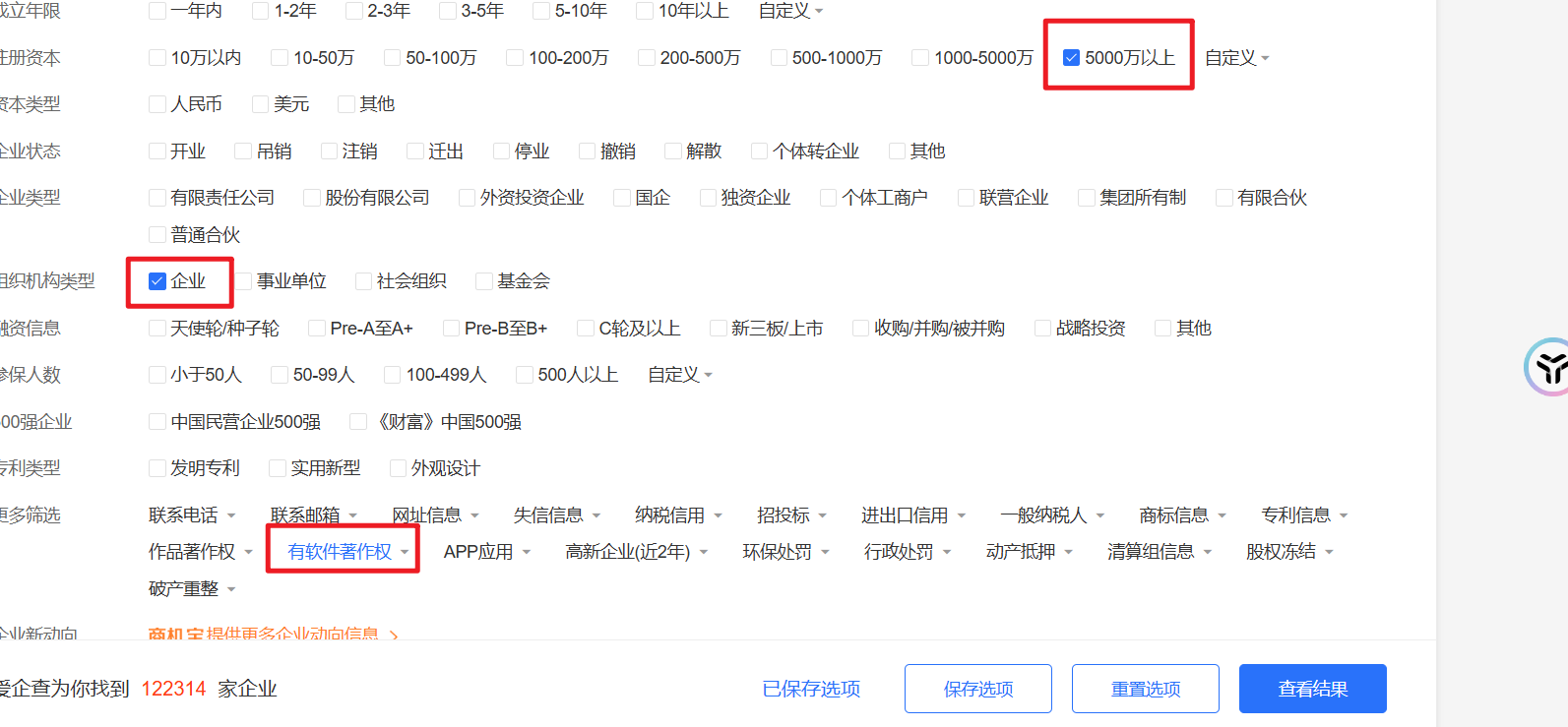
深度挖掘 CNVD的挖掘,其很重要的一步就是要先确定资产(注册资产超过5000w),网上有不少的文章,也有讲怎么锁定资产,但是我还是太懒了,我还是喜欢直接上手的。
当我们直接去企查查上面去看,你会发现没有什么思路,怎么多公司,我们怎么获取到资金大于5000w的资产,这玩意在高级搜索里面倒是有,我这种小平民用不起高级搜索(企查查贵),但是爱企查挺便宜啊,新用户4.9体验七天,而且这点米的回报率还挺高,我们可以收集导出文件夹,长久保存都没有问题(记住关闭自动续费,不要当了大怨种!!!),ok爽用!!!
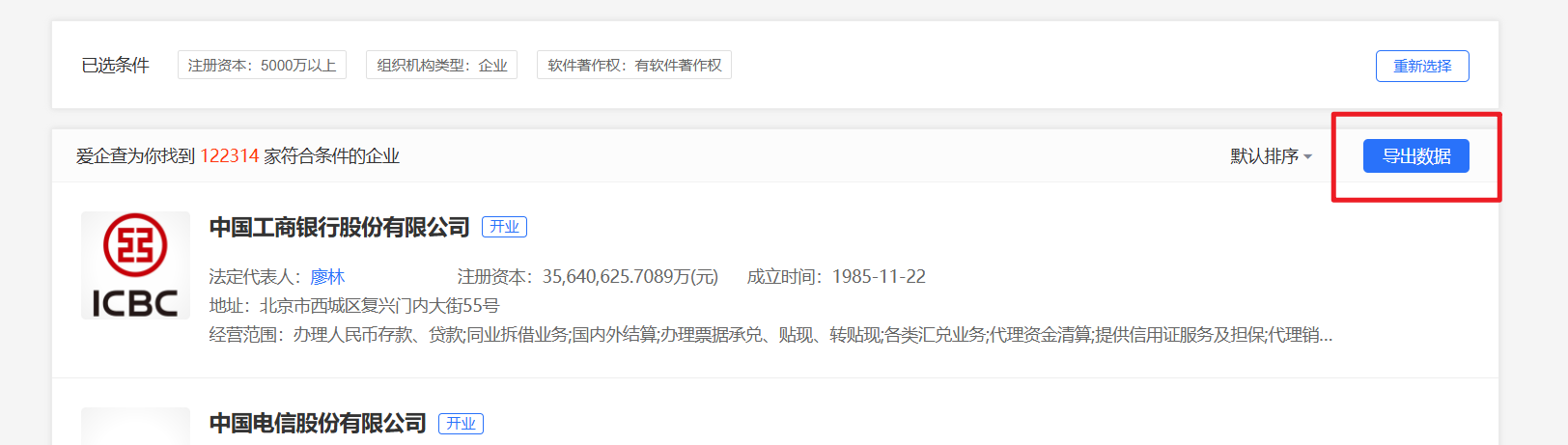
12万家,查询到直接导出
不过这里导出后生成文件要等一阵
这个就不等了,给师傅们看看导出结果
我们直接进行下一步,挖掘肯定要挖新的,或者挖很旧的软件,那就看看如何筛选,我们直接选择一个中间段的公司,保证难度稍微减小的同时,也保证了软件的使用数量,能更好找到多个案例,直接来个500页看看
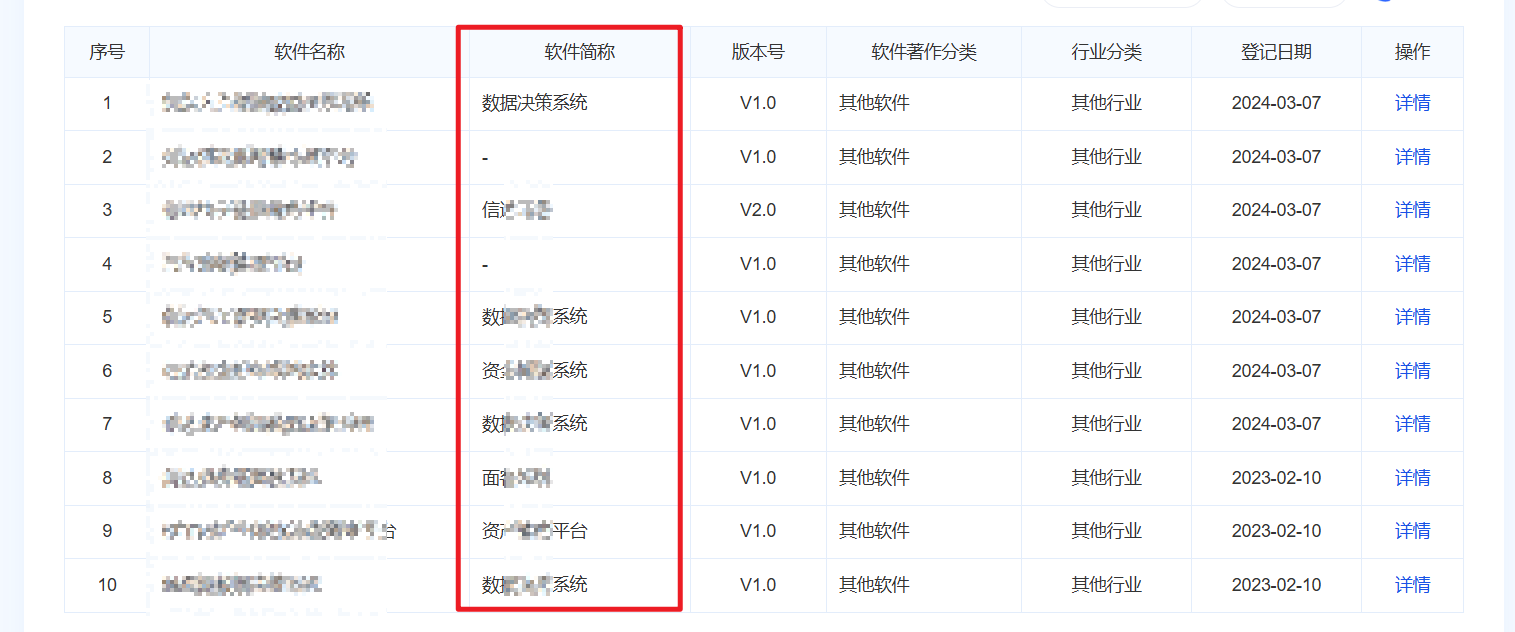
然后随便挑选一个企业,打开其软件著作权信息
然后选择软件简称,因为如果直接使用软件名称(并不绝对),使用搜集到的资产很少,甚至没有,还有就是要注重分辨一下,这个软件简称,有的可能是APP,所以我们检索的时候最好还是检索“xxx系统(这里系统都不一定准)、xxx平台”这种。
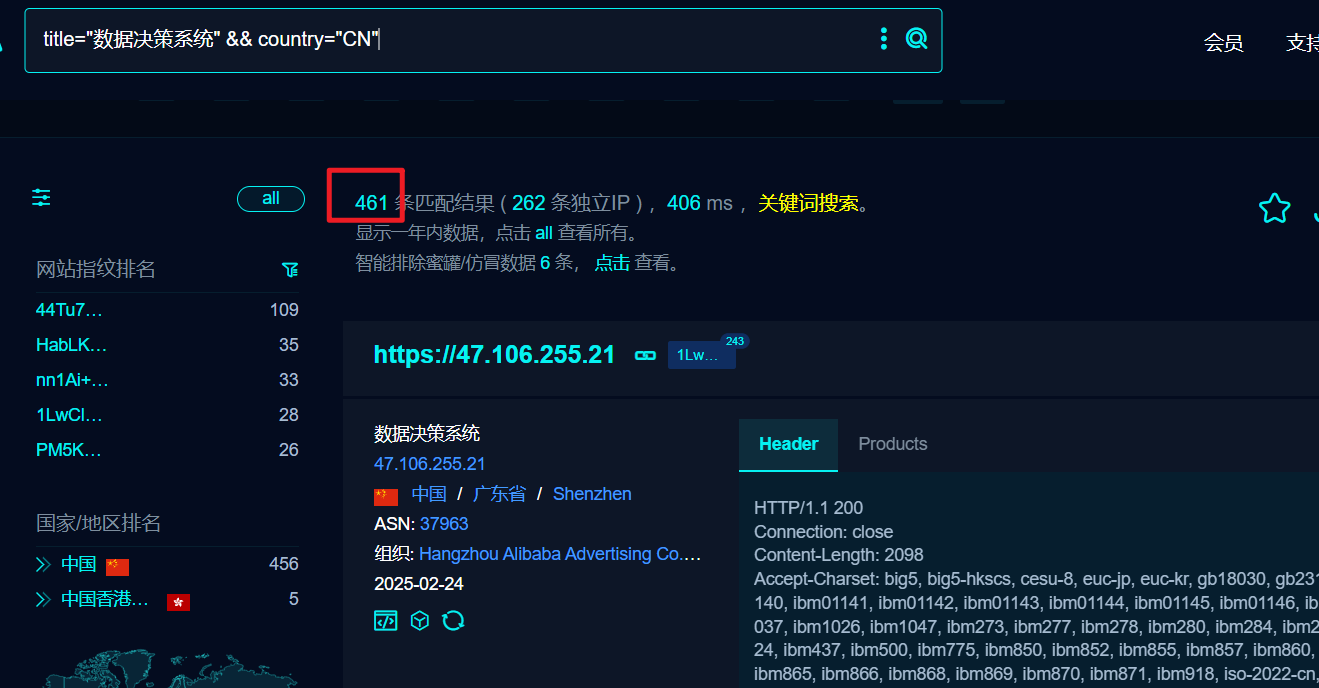
然后选择这么一个,直接上fofa,可以看到搜索结果还是有不少
我们也就这么锁定了一个系统。不过这里还是要仔细一点,我们打开几个站点,看看样子,如果差不多满足10以上,我们再挖挖,还是避免打偏 嘛
还有就是,我们再检索一些系统的时候,可以借用fofa的icon图标查询,从而防止打偏
CNVD的信息收集 这里就是老生常谈的了,github信息收集、google黑语法
再放一遍github搜索语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 in :name baidu #标题搜索含有关键字baiduin :descripton baidu #仓库描述搜索含有关键字in :readme baidu #Readme文件搜素含有关键字stars :>3000 baidu #stars数量大于3000 的搜索关键字stars :1000 ..3000 baidu #stars数量大于1000 小于3000 的搜索关键字forks :>1000 baidu #forks数量大于1000 的搜索关键字forks :1000 ..3000 baidu #forks数量大于1000 小于3000 的搜索关键字size :>=5000 baidu #指定仓库大于5000 k(5 M)的搜索关键字pushed :>2019 -02 -12 baidu #发布时间大于2019 -02 -12 的搜索关键字created :>2019 -02 -12 baidu #创建时间大于2019 -02 -12 的搜索关键字user :name #用户名搜素license :apache-2 .0 baidu #明确仓库的 LICENSE 搜索关键字language :java baidu #在java语言的代码中搜索关键字user :baidu in:name baidu #组合搜索,用户名baidu的标题含有baidu的等等
google dork
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 邮箱配置信息泄露site: github.com "google.com" smtp passwordsite: github.com "google.com" smtp @126 .comsite: github.com "google.com" String password smtpsite: github.com "google.com" root passwordsite: github.com "google.com" sa passwordsite: github.com "google.com" User ID=site: github.com "google.com" svnsite: github.com "google.com" svn passwordsite: github.com "google.com" svn usernamesite: github.com "google.com" svn username passwordsite: github.com "google.com" inurl:sqlsite: github.com "google.com" passwordsite: github.com "google.com" ftp ftppasswordsite: github.com "google.com" 密码site: github.com "google.com" 内部
这些都可以用了试试
除此之外,我们还可以在一些社交平台上去碰碰运气,根据产品具体名去搜索侦察,相信大数据会给你自动模糊匹配的!!!
有时会有产品的交流群,也可以尝试去购买产品源码,那不是更得心应手了?
分享就到此结束了,希望能够帮到师傅们,如果有什么不对的地方,还请斧正,最后祝师傅们漏洞多多!!!